
TL;DR
이번 포스팅에서는 리뷰할 논문은 지난 19년 11월에 나온 StyleGAN v2를 리뷰 해 보겠습니다
StyleGAN 에 이어서 2 번째 논문인데, 이번 버전에서는 어떤 문제점들을 어떻게 해결했는지를 한번 보려고 합니다!
아래는 StyleGAN v2 로 생성한 이미지들 입니다.
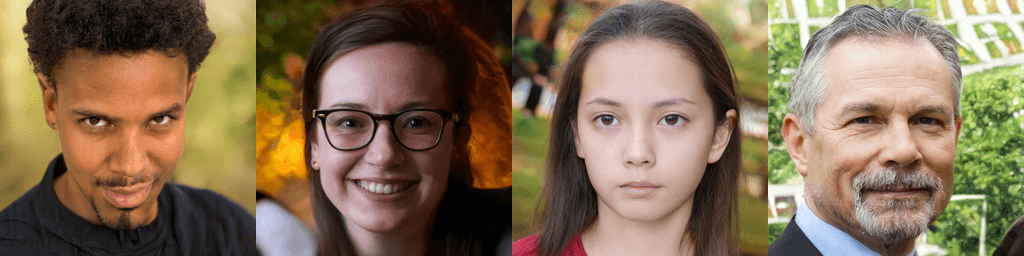
paper : arXiv
official implementation : code
Related Work
요건 이전 버전 StyleGAN paper 입니다.
- StyleGAN : arXiv
Introduction
이번 논문에서는 이전에 발표한 StyleGAN 의 artifacts 들에 대해 지적하면서 시작합니다.
요약 해 보면 크게 3개의 문제점을 지적 / 개선 / 해결 했는데,
- blob-like artifacts
- artifacts related to progressive growing
- metrics for evaluating GAN performance
blob-like artifacts
StyleGAN 에서 Instance Normalization 이 아래 이미지 처럼 water droplet 과 같은 artifacts 를 발생한다고 합니다.

generator 의 activation map 을 보면 (오른쪽 사진들) 자국 같은 것 들이 보일텐데, 설계상 때문에 요게 문제가 됐다는 겁니다.
그래서 StyleGANv2 에서는 새로운 normalization method 를 사용해서 이 문제를 해결합니다.
artifacts related to progressive growing
high-resolution GAN 에서 stable 한 훈련을 위해 low resolution 부터 훈련을 시작하는 progressive 한 훈련 방식을 해 왔었는데, 이전에는 각 resolution 마다 같은 network 구조를 사용했는데, 다른 resolution 을 훈련할 때는 다른 network topology 를 사용해야 한다는 말 입니다.
매 resolution 마다 같은 구조가 아닌 다른 구조로 학습을 하게 되면, 각 resolution 에 맞게 더 효율적으로 훈련할 수 있다는 논문피셜 입니다. (당연한 이야기긴 하지만)
metrics for evaluating GAN performance
GAN 생성 이미지 quality 를 측정하기 위해 여러 metric 들을 사용하는데 (e.g. FID, precision, recall), 이런 metric 들의 문제점을 제기하고 새로운 gan metric 을 사용해서 performance 를 측정했다고 합니다.
간단하게 설명 해 보면, 위에 소개된 이전 metric 들은 inception v3 같은 base network 에 기반해서, 전반적인 texture 보다 shape 같은 것에 집중을 하는데, 결론적으로 이미지 quality 전반적인 면을 capture 하지 못한다는 말 입니다.
그래서 이런 문제가 어느 정도 해결 한 perceptual path length (PPL) metric 을 사용했다고 합니다.
etc
마지막으론 latent space 가 더 잘된다고 하네요
Architecture
결론적으로 아래와 같은 변경 사항들로
- characteristic artifacts 들을 제거하고
- full controllability 를 유지한다.
removing normalization artifacts
위에 introduction 에서 instance normalization 때문에 blob-like 한 artifacts 가 생긴다고 했는데, 최종 이미지 (1024x1024) 에서는 안 보일 수 있어도, 중간 이미지 (64x64) 쯤 부터 발생하는 걸 볼 수 있는데, 이런 부분을 discriminator 에서 잡을 수 있어야 하겠죠?
AdaIN 같은 operation 이 각 features 별 mean, variance 를 따로따로 normalize 하기 떄문이라 원인을 밝힙니다. (논문에선 generator 가 의도적으로 signal strength 정보를 이전 IN 으로부터 sneak 한다고 표현돼 있어요)
결론은 이런 normalization step 이 없어지면 이런 droplet artifacts 가 없어질 거라 합니다.
generator architecture revisited
아래가 과거 (StyleGAN) / 현재 (StyleGANv2) generator architecture 비교 샷 인데, AdaIN operation 을 normalization, modulation step 으로 분리해서 보여줬네요.
과거에는 bias 하고 noise 를 style block 에 적용 해 줬는데, 이런 상대적인 영향이 게 style magnitude 에 반비례하게 적용된다고 합니다.
그래서 이런 operation 을 style block 밖으로 빼면서 조금 더 predictable 한 결과를 가져갈 수 있었다고 해요.
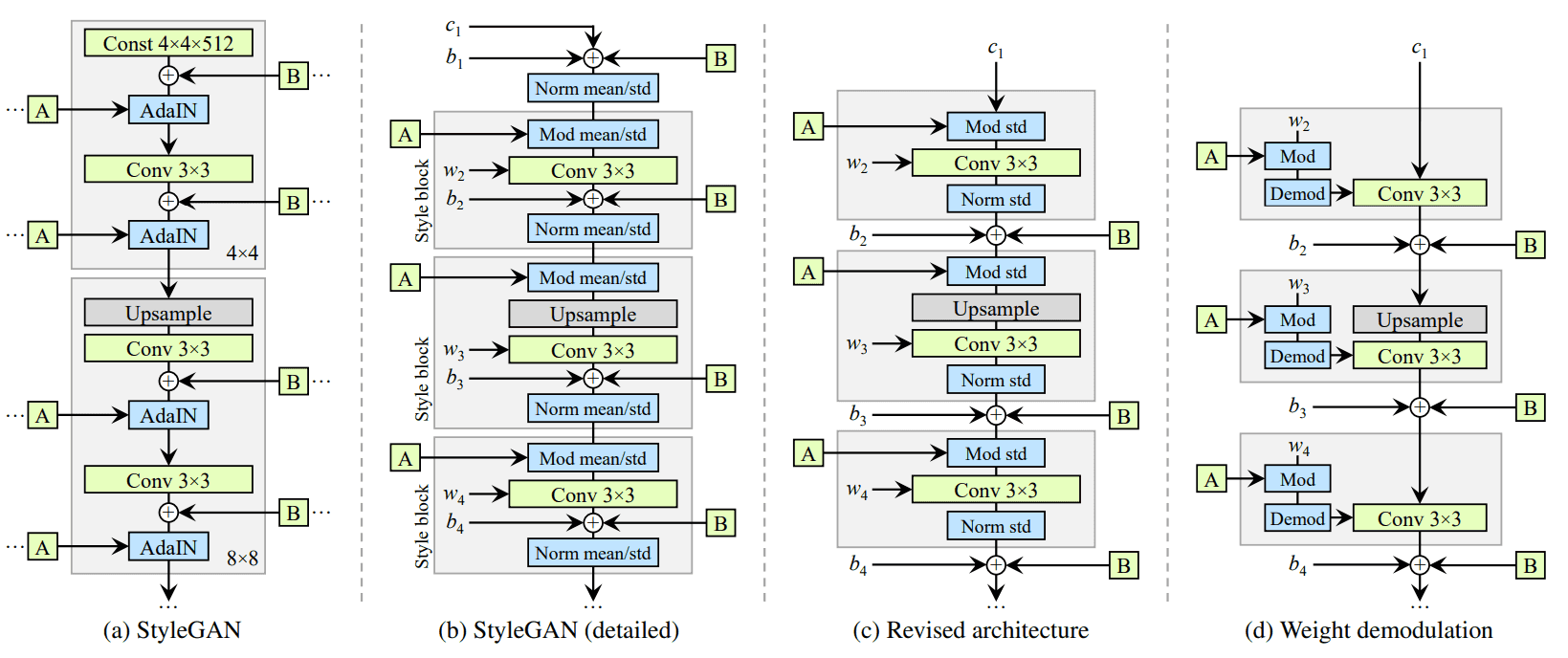
그리고 한 가지 더, AdaIN (normalize & mod) 를 mean, std 둘 다가 아닌 std 에만 적용 하는 것만으로도 충분 하다고 합니다.
instance normalization revisited
이전 instance normalization 은 style 에 너무 strong 한 영향을 끼쳤었고, 이를 그럼 어떻게 scale-specific 영향을 style 에 그래도 주면서, 좀 relaxing 할 수 있을까 했는데,
- 일단 batch normalization 은 안됨. (small mini-batches 에서 high-resolution synthesis 엔 부적합)
- 그냥 instance normalization 제거. -> 실제로 성능 증가 (효과있음)
그런데, 이렇게 제거 해 버리는 것은, scale-specific 보다 style cumulative 한 거에 영향을 주었고, StyleGAN 의 controllability 를 잃어 버리게 됐답니다.
그래서 새로운 방법을 제안했는데, controllability 를 유지하면서, instance normalization 으로 인한 artifacts 는 제거하는 방법.
modulation, convolution, normalization 에서 modulation 부분을 생각 해 보면,
들어오는 style 에 의해서 (위 그림에서 A) modulation 각 convolution 의 feature map 을 scale 하는데, 이 부분을 아래처럼 구현이 가능 합니다.
는 일반 weight 이고, 이 modulated weight, 는 scale 인데, 번째 input feature map, 는 output feature map 에 해당.
이렇게 하게 되면, 위 처럼 제안된 instance normalization 은 effect 를 output feature maps distribution 에서 제거할 수 있어요.
결론적으로 위에 (d) 그럼처럼, 이제 style block 은 하나의 convolution layer 로 구성될 수 있네요. (conv weight 는 에 의해 adjust 됨)
(논문 뒤엔 이거에 대한 이야기가 더 있는데 skip)
그래서 아래와 같이 blob-like artifacts 들을 해결 했답니다.

etc
training technique 들도 몇 개 소개되었는데, 그렇게 여러 기술들이 덕지덕지 적용되지 않고 깔-끔 합니다.
다른 거 붙이는 거 비해 computation cost 가 적게들고, memory 사용량 down 등의 이유를 들었네요.
- Loss : logistic loss
- Lazy Regularization : regularization (every 16 mini-batches 마다 1 번)
- Path Length Regularization : poor local conditioning 을 피해기 위한 method 인데, Jacobian Matric 연산의 heaviness 를 해결하기 위해 identity 등을 사용 하는 등 이야기가 논문에 나옵니다.
결론적으로, 조금 더 reliable 하고 consistently 동작하는 모델이 됐다고 캅니다.
가 orthogonal matrix 니, 이런 matrix 는 lengths 를 보존하겠죠? (어떤 dimension 에 대해서 squeezing 없고)
constant 가 training 중 path lengths 의 exponential moving average 값을 optimize 되게 해 줍니다
Experiment Result
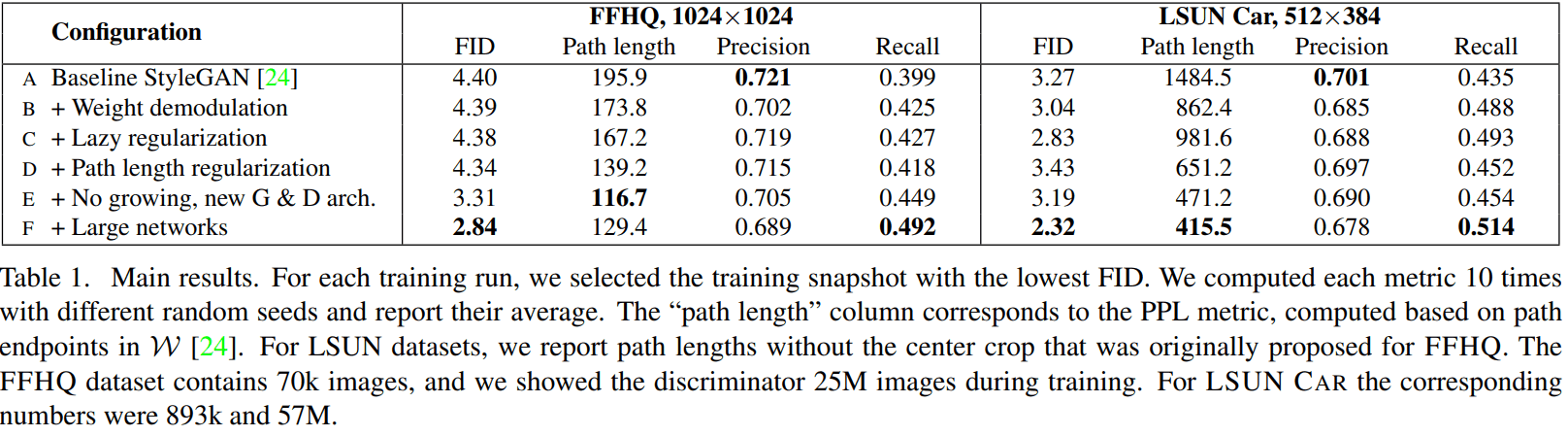
FFHQ / LSUN Car dataset 에서 퍼포먼스는 아래와 같아요. 총 4가지 metrics 을 사용해서 evaluate 했습니다.
- Frechet Inception Distance (FID)
- Perceptual Path Length (PPL)
- Precision
- Recall
이 외에도 이전 StyleGAN 과 PPL distribution 차이 여러 가지 analysis 가 있습니당
나머지는 논문 참고하세요~ (귀찮)
Conclusion
이번 논문도 엄청 재미있는 approach 들이 많아서 재밌었는데, 매번 느끼지만 nvidia labs 는 이전 연구들의 root cause 를 잘 잡고 좋은 결과들을 매번 보여주네요.
결론 : 마음에 드는 논문