
TL;DR
이번 포스팅에서는 리뷰할 논문은 SAN (Second-order Attention Network) 이라는 Image Super Resolution task 에서 현재 여러 test set 에서 제일 높은 성능 (19년도 기준)을 보이고 있는 architecture 입니다.
이 때 까지도 여러 attention module 들을 붙여서 super resolution network 의 성능을 올리는 데 trend 였는데, 재밌는 (?) approach 를 해서 리뷰 해 보게 됐습니다.
paper : CVPR19
official implementation : code
Related Work
요건 다른 Super Resolution 들 paper list 입니다.
Introduction
이전에 여러 SISR (Single Image Super Resolution) task 들의 network 들은 더 넓고 깊은 구조를 띄면서, 상대적으로 network 의
- representation 능력
- 각 중간 layer 들의 feature correlation
들을 덜 고려하는 경향을 보였다면서, 이번에 SAN (Second-order Attention Network) 를 제안하면서, 이런 문제들을 더 고려한 구조를 맨들어 봤다고 캅니다.
기존 SE (Squeeze and Excitation) Module 은 Squeeze stage 에서 GAP (Global Average Pooling) 을 하면서 first-order distribution feature 밖에 학습하지 못했는데, 여기 SOCA Module 이라 부르고 attention network 에선 second-order-tic 하게 연산을 위한 operation 이 들어가서 adaptive 하게 feature 를 rescaling 했다고 하는데, 궁금해지네요.
Architecture
SAN 는 4 가지 부분으로 구성이 되어 있는데요,
- shallow feature extraction
- non-locally enhanced residual group (NLRG)
- up-scale module
- reconstruction part
입니다.
전반적인 SAN architecture 는 아래 사진과 같습니다.
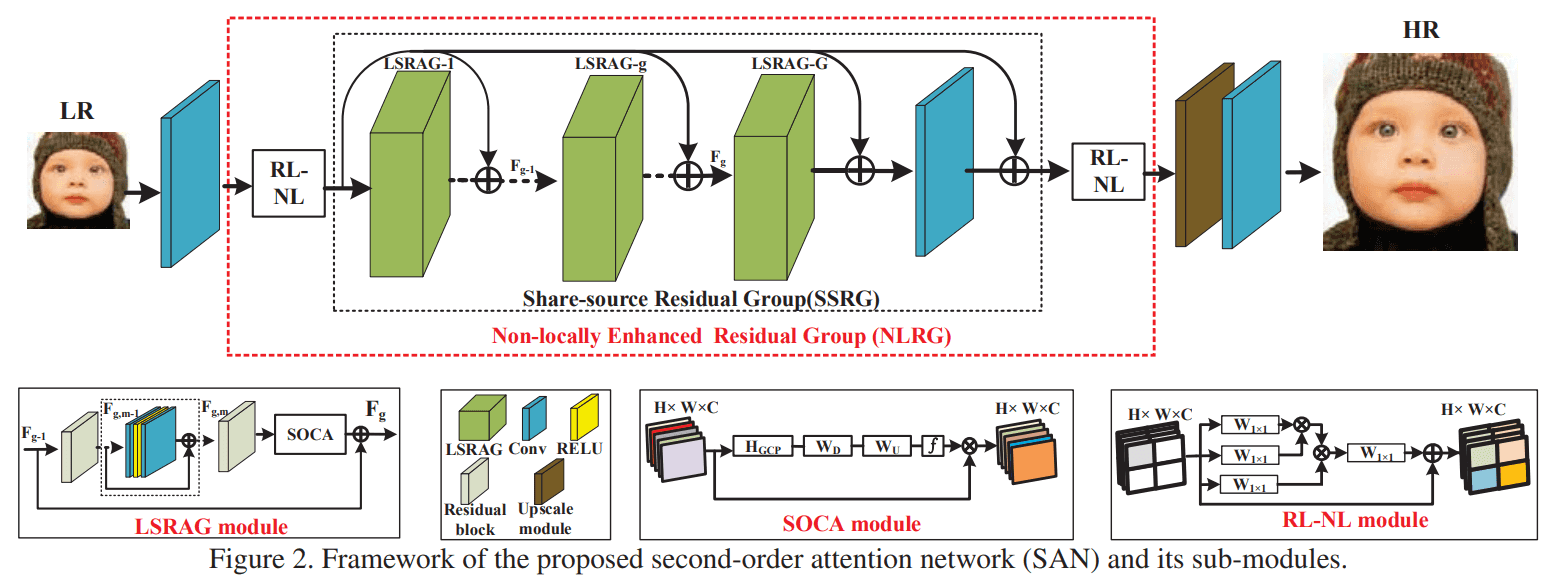
1. shallow feature extraction
논문에서 자기들은 shallow feature extraction 을 위해서 LR (Low Resolution) 이미지로 부터 오직 convolution layer 1 층만 쌓았다고 합니다.
그냥 평범한 convolution2d 하나입니다.
2. non-locally enhanced residual group (NLRG)
MLRG module 은 크게 2 가지로 구성되어 있는데,
- 여러 개의 region-level non-local (RL-NL)
- 하나의 share-source residual group (SSRG)
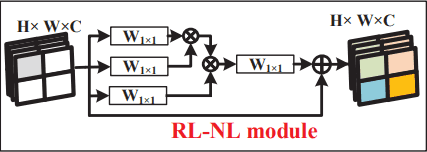
RL-NL
논문에서 RL-NL Module 은 LR 에서 구조적인 feature 들을 잘 따내고, HR 의 nature-scene 의 self-similarities 도 잘 가져올 거라고 합니다.
위치 상으로 역할이 SSRG 구조 이전/후에 사용되면서, high-level 에서 여러 넓은 범위의 정보들을 잘 catch 하는 module 이네요.
논문에서 이전에 global-level non-local operation 을 사용 하는 거에 대한 한계점들을 들었는데요,
- unacceptable computational burden
- non-local operations at a proper neighborhood size are preferable for low-level tasks
즉, global-level 에서 사용하면, feature size 가 큰 경우에 연산이 너무 heavy 해 진다는 단점과, 주로 이런 연산들은 low-level, global-level 이 아닌 곳에서 사용되었다 라는 점인데요.
그래서 이 논문에선, region-level 에서 해당 연산을 합니다. 즉 k x k 개의 regions 들로 나누고, 해당 region 들에 대해서 non-local operations 을 합니다.
아래는 RL-NL Module 구조 사진입니다.
SSRG
SSRG 는 Local Source Residual Attention Group (LSRAG) 들이 share-source skip connection (SSC) 로 구성 되어 있습니다.
LSRAG Module 은 simplified residual blocks (w/ local-source skip connection) 들로 구성이 되어 있고, feature inter-dependencies 를 잘 구하기 위한, 이 논문에서 제안한 SOCA Module 들이 붙어 있습니다.
특징은 다른 SR architecture 보다 light 하게 network 를 쌓았는데, 논문에서 residual blocks 을 깊게 쌓으면 여러 가지 문제가 있을 수 있다며 LSRAG Module 을 기본 param 들을 사용했다고 했어요.
그냥 이렇게 간단하게만 쌓으면 좋은 성능이 나올 수 없다고 하면서 share-source skip connection (SSC) 를 언급했는데요, SSC 사용으로 깊은 network 를 잘 훈련 시키면서 충분하게 LR 이미지로 부터 low-frequency 정보들을 잘 가져올 수 있다고 합니다.
아래와 같은 convention 으로 쌓았는데, LSRAG 번 째 group 을 식으로 표현하면 이렇게 계산합니다.
는 convolution weight 인데 0 으로 초기화를 하고, 학습하면서 점차점차 shallow feature 들을 add 하는 방향으로 학습합니다.
bias 는 false 네요 (배우신 분)
결론적으로 SSRG structure
아래는 LSRAG / SOCA Module 구조 입니다.

Second-Order Channel Attention (SOCA)
Introduction 에서 간단하게 설명은 했는데, 구체적으로 한번 다뤄볼께요.
이전 channel-attention module 에서 squeeze stage 에선 GAP 등의 연산을 통해 정보를 압축했어요. 즉, first-order statistics 이상의 정보를 고려하지 않았다는 것을 논문에서 언급합니다.
Covariance Normalization
Covariance Normalization 를 하는 이유는, 더 discriminative representation 을 학습하는 데 중요한 역할을 한다고 하네요.
간단한 연산이니, 아래 공식만 적어두겠습니다.
결론적으로, 일 때, eigenvalues 들이 non-linear 하게 잘 동작하고, 일 때 제일 좋다고 하네요.
이후 Channel-Attention part 는 SE operation 하고 동일합니다.
즉, 연산적으로 결론은 기존 Global Average Pooling (GAP) 대신 Global Covariance Pooling (GCP) 로 바꾼겁니다.
이후에 GPU 에서 EIG 를 빠르게 구하기 위해서 Newton-Schulz iteration 을 했다고 하는데, 이 부분은 생략하겠습니다.
3. up-scale module
논문에서 여러 이유를 들려고 하는데, 결론은bi-linear up-sampling 을 사용했어요.
4. reconstruction part
이 부분도 특별한 점 없이 RL-NL Module 이후 convolution layer 1 층 쌓은 구조 입니다.
Etc
- Channel-Attention 때 fc 가 아닌 1x1 conv2d 로 projection 함.
- reduction ratio 는
- 나머지 convolution 들 kernel size = 3, channel = 64
- LSRAG Module group = 20
- RL-NL
- residual block, single SOCA module at the tail
Experiment Result
Set5 PSNR Performance
논문에서 제안된 각 module 들을 one by one 추가 했을 때 성능 차이를 보여주는데, 확실 하게 FOCA vs SOCA 비교만 봐도 성능 차가 있네요.

Urban100 PSRN / SSIM Benchmark
이전에 나온 다른 논문들하고 성능 비교를 해 봐도 SAN 이 확실하게 성능이 더 좋은걸 볼 수 있네요

Computational and Parameter comparison
network 규모 대비 성능을 비교해 놓은 benchmark table 인데, 꽤 괜찮은 가성비(?)를 보이네요.

Conclusion
뭔가 attention 끝을 보려고 하는 논문이네요.
SISR task 도 요즘 light-weight 지향하는 trend 도 많이 보이고 있는데, 이 쪽 연구 쪽도 재밌는 게 많이 나오면 좋겠네요.
결론 : 기승전 attention