
TL;DR
최근 computer vision architecture를 보면 image 만 사용하는 게 아닌 extra training data로 text information를 활용하면서 성능을 끌어올리거나 여러 models를 ensemble 하는 Model soups 같은 approaches가 나오고 있는데, 또 다른 hybrid 모델 + 제목부터 Global Context를 고려한 ViT 라길래 기존 SwinTransformer 나 Focal 과는 어떻게 다를지 궁금해서 읽게 됐습니다.
Related Work
Architecture
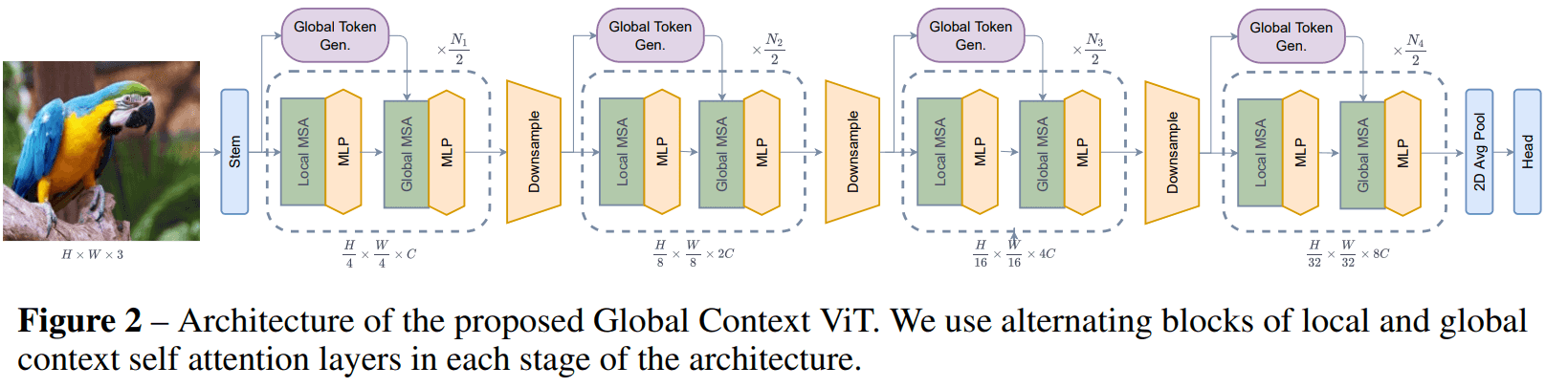
전반적은 design 은 FocalNet, SwinTransformer 느낌처럼 hierarchical 한 구조인데, 차이점만 보면 다음과 같습니다.
- Global Token Generator module
- Local / Global MSA
- Downsample module
Global Query Generator
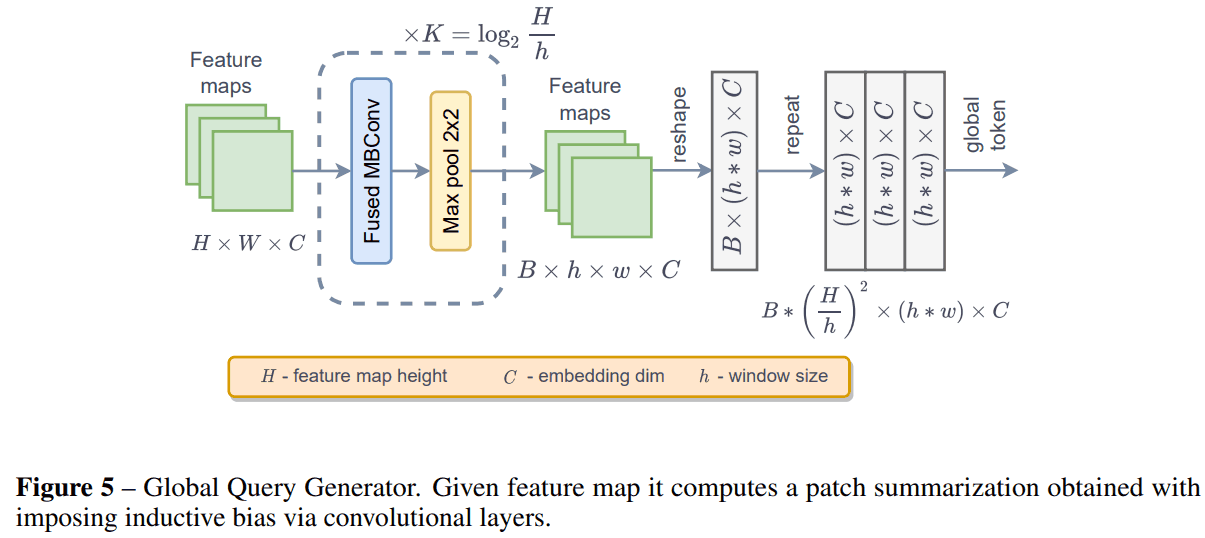
이번 논문에서 Global Context를 더 잘 이해하기 위해 제안한 Global Token 이란 개념인데, global context를 잘 이해하기 위해 local patch 가 아닌 entire input feature에 대해서 잘 compress 해서 global feature를 생성합니다.
각 stage 초반에 compute 하고 아래 소개할 Global Attention을 할 때 query 부분에 넣어주는 방식입니다. module design 은 간단한데, fused mbconv 후 max-pool 해 줍니다.
Global Self Attention

architecture를 보면 각 stage 별로 local attention 후 global attention을 수행하는데, global attention을 수행할 때 stage 초반에 Global Query Generator 가 생성한 query token를 query로 넣어주는 부분에서 차이가 있습니다.
Downsample module
은 이전 연구 (EfficientNetV2)에서 사용하던 모듈과 큰 특별한 점이 없는데, pooling layer를 max-pool 이 아니라 conv strided pool 한 점에서 차이가 있습니다. Fused-MBConv design 은 아래와 같습니다.
% DW-Conv : Depth-Wise Convolution % SE : Squeeze and Excitation % LN : Layer Normalization
Performance
ImageNet-1K benchmark
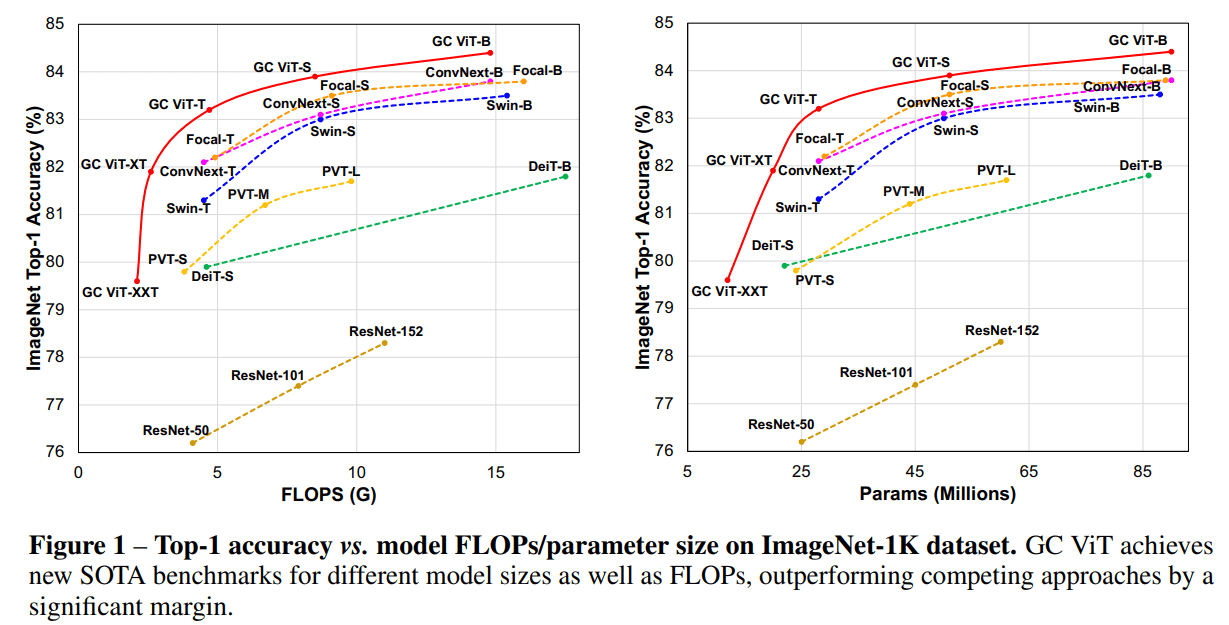
FLOPs, parameters 대비 GC VIT 가 가장 좋은 성능을 보여주고 있습니다.
MSCOCO benchmark
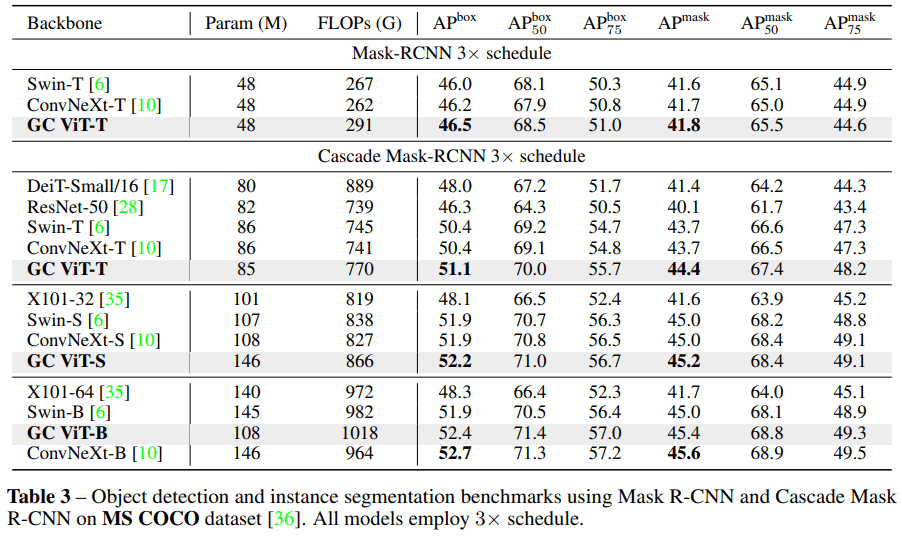
Object Detection task에서도 비슷한 scale에 있는 모델들 대비해 좋은 성능을 보여주고 있습니다. base 모델에선 ConNeXt 가 더 좋네요.
Various Components benchmark
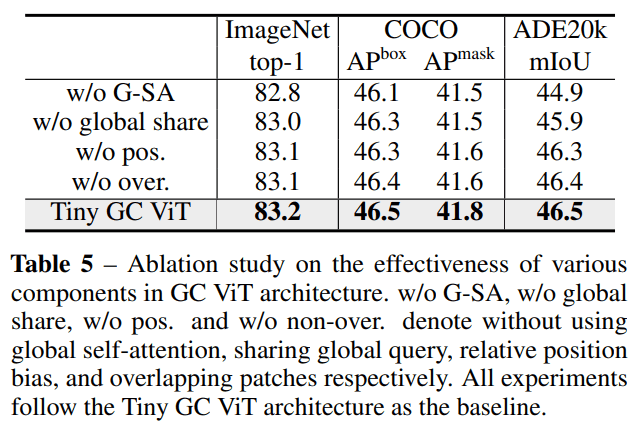
연구에서 제안한 Global Token 이 얼마나 영향이 있는지도 확인했는데, global self-attention을 제거했을 때가 performance drop 이 가장 컸다고 한다.
Conclusion
갠적으로 Global Token을 stage 별로 생성하고 global attention을 한다는 점에서 직관적이고 정말 간단한 방법이면서 FLOPs 대비 성능도 훨씬 좋아서 재밌게 본 연구였다. 또, 이런 design 이 SwinTransformer 나 Focal Transformer 보다 더 깔끔한 거 같다 생각한다.
결론 : 굳굳