
TL;DR
오랜만에 speech-synthesis 쪽 논문을 보다가 (LJSpeech dataset에서) MOS, CMOS metrics에서 human-level에 도달한 research 가 있는데, 거기에 최근 유행이었던 diffusion approach 가 아닌 점에서도 꽤 흥미로웠습니다.
코드는 아직인가 보다
Related Work
Architecture
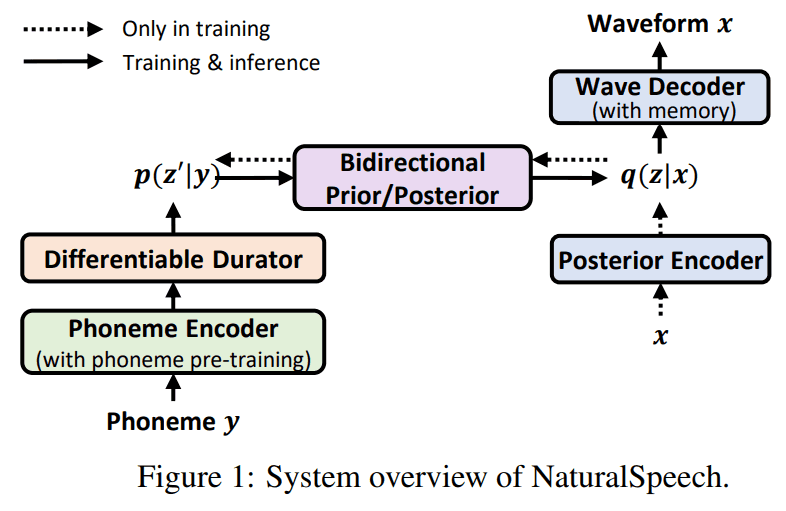
이번 연구는 총 4가지 부분에서 contributes 했다.
- pre-train large-scale langugae model on phoneme sequence
- differentiable durator
- bi-directional prior/posterior module
- memory-based VAE (memory bank)
Phoneme Encoder
phoneme encoder는 말대로 phoneme sequence 를 encode 하는 module인데, 이전 연구들은 일반 dataset으로 학습하거나 phoneme에 대해서만 학습한 LM을 사용해서 phoneme domain에 어울리지 않거나 capacity issue로 positive boost를 주지 못했다고 합니다.
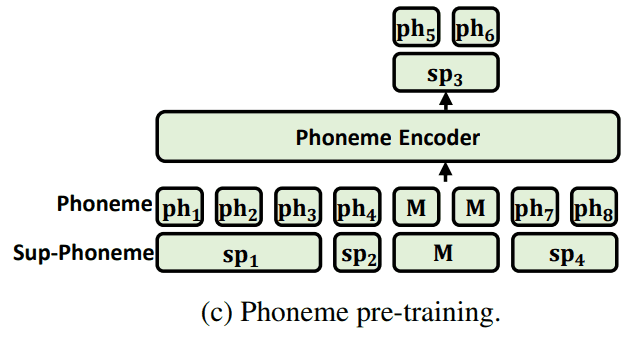
그래서 이번 연구에선 phoneme에 대해서만 학습하는 게 아닌, mixed-phoneme (phoneme + sub-phoneme) pre-training을 했다고 합니다.
또한, MLM 학습할 때 phoneme tokens과 sub-phoneme tokens 둘 다에 대해서 MLM 학습합니다.
Differentiable Durator
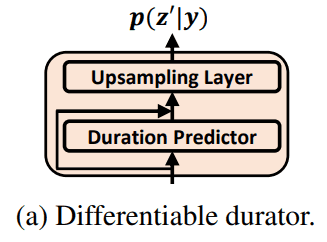
architecture에 나온 것처럼, 위 phoneme encoder에서 나온 phoneme-level phoneme representation 이 durator ()의 input으로 들어오고 output으로 priro distribution 을 줍니다.
다음과 같이 쓸 수 있습니다.
where
구체적으로 durator는 총 3가지 역할을 합니다.
- each phoneme에 대해 duration 예측
- up-sampling module에서
phoneme-level을frame-level로 upsample 해 줌 - priro distribution의 mean/variance를 calculate 하는 module (prior 는 standard isotonic multivariant Gaussian. VAE scheme에 따라서)
- train / inference time에서 predicted duration mismatch를 최소화하려고
Bi-Directional Prior/Posterior Module

bidirectional prior/posterior module 은 phoneme 으로 부터 오는 와 speech 로부터 오는 의 information gap을 줄이기 위해 만들었다고 합니다.
위 그림처럼 KL divergence를 각 방향(?)에서 서로의 KL divergence loss를 optimize 하도록 학습합니다.
module 은 flow model을 채택했고 이윤 inverse 가능해야 하고 optimize 쉬워야 하기 때문이라고 합니다.
reduce posterior 와 backward mapping , enhanced prior 와 forward mapping 간 KL을 최소화하는데, 구체적인 전개 수식은 논문에
memory-based VAE
posterior 는 원래 VAE에서 speech waveform reconstruction 할 때 쓰여서 prior 보다 complex 한데, 요걸 간단하게 하려고 memory-based VAE를 제안합니다.
를 speech reconstructio 에 그대로 사용하지 말고, 를 attention query로 사용하고, attention output를 waveform reconstruction에 사용하자는 아이디어입니다. 즉, posterior 는 아래 그림처럼 memory bank에 attention weights를 구할 때만 사용됩니다.
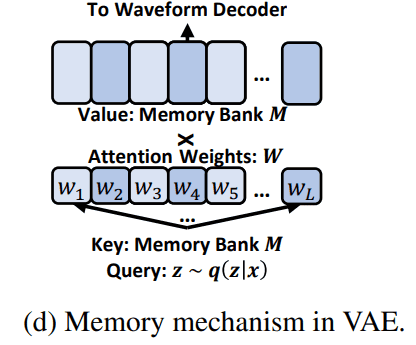
reconstruction loss를 써 보면 다음과 같습니다.
- = waveform decoder
- () = memory bank
- () = attention parameters
- = size of the , = hidden dimensions
Training Recipe
전체 loss는 다음과 같습니다.
gradient flow 가 수식으론 복잡한데, 아래 그림으로 보면 이해가 더 쉽습니다.
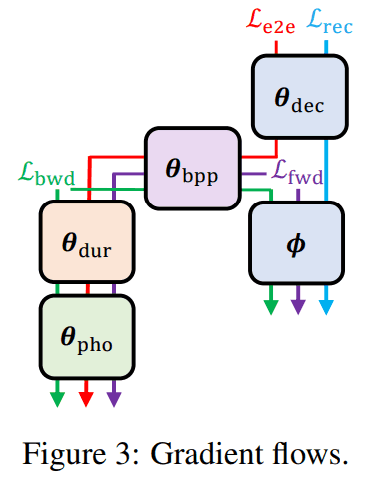
train & inference flows

Performance
MOS/CMOS on LJSpeech
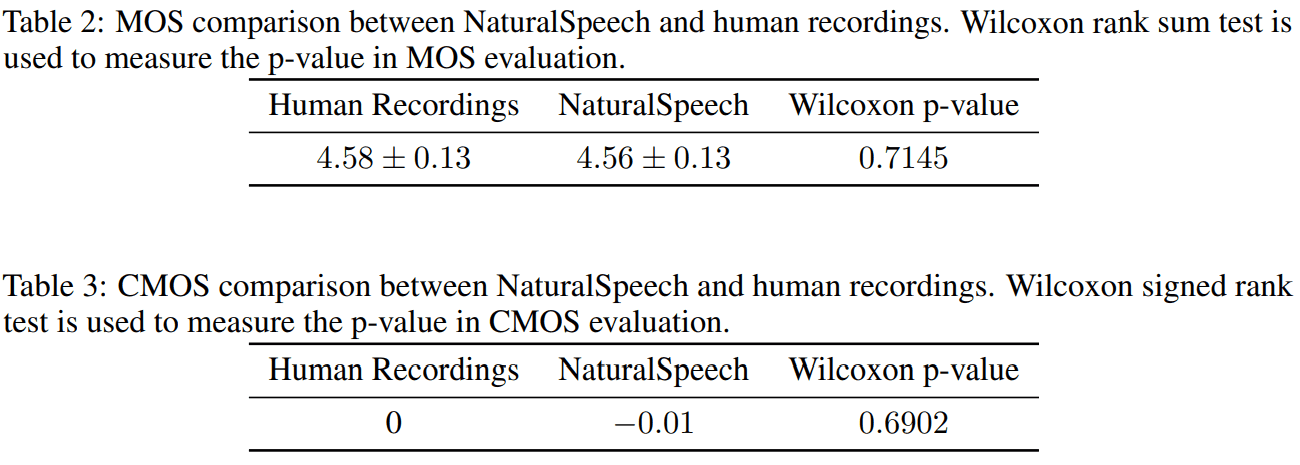
MOS, CMOS metrics에서 통계학 적으로 유의미한 분포 차이가 없음을 보여준다.
Benchmark on LJSpeech

절대적 차이로도 꽤 큰 차이가 난다.
Modules

이번 연구에서 제안한 ideas 중 하나 씩 빼고 학습했을 때, 모두 metric에 큰 영향을 주고 있다.
Inference speed

RTF 도 FastSpeech 2 + HiFiGAN, VITS와 comparable 하고 빠른 수준이다.
Latency
Conclusion
LJSpeech dataset에서 human-level metrics을 달성했다는 점에서 promising 했고, novelties 나 architecture 도 갠적으론 마음에 드는 구조였다. 다른 dataset에서 benchmark 결과도 궁금한데 포함해 주면 좋겠다.
결론 : 굳굳