
TL;DR
대부분 memory & speed 관점에서 attention 연구를 보면, full attention 하지 않는 방식이나 유사(?) attention을 만들거나 softmax 부분 연산을 줄이는 등의 시도들이 있었는데, 이번 연구는 hardware-level에서 memory (종류) + kernel fusion 해서 속도 + 메모리를 잡은 연구라 재밌어서 읽게 됐습니다.
- paper : arXiv
- code : github - official
- code : github - triton
Related Work
Architecture
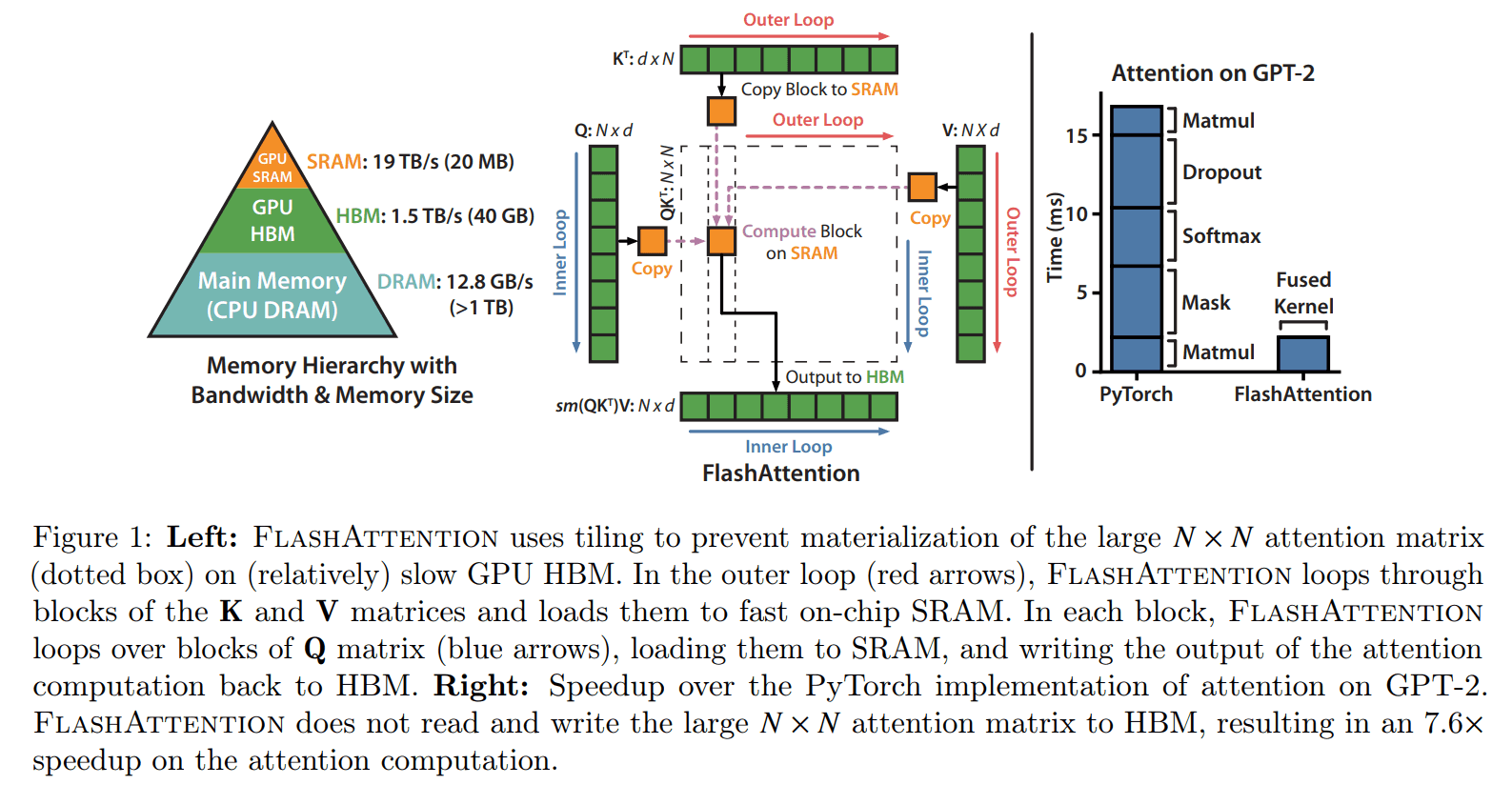
기존의 pytorch implementation의 attention 은 모두 HBM 위에서 동작했는데, FlashAttention 은 한 땀 한 땀 cuda로 구현해 상대적으로 높은 bandwidth을 가지는 SRAM를 활용해서 memory와 speed를 빠르게 했다는 점이다.
크게 3가지 부분에서 contribute 했다.
- tiling 함 (increamental 하게 softmax redunction 진행)
- softmax normalization factor 저장하기. (on-chip에서 recompute 하는 편이 HBM에서 attention matrix 읽는 것보다 더 빠르다 함)
- block-sparse attention 도 만들어봤다
Tilling
위 brief architecture에 나온 것처럼 HBM 위에서 attention 이 연산되는 것을 빠르게 하기 위해서 tilling & recomputation을 합니다.
- , , matrices를 blocks으로 split 후, HBM -> SRAM 으로 copy
- (SRAM 위에서) 해당 block에 대해 attention 계산
tilling 시, softmax는 columns에 대해서 연산하니 scaling + large softmax decomposition 합니다.
numericla statbility 확보를 위해, softmax vector 에 대해서,
, , ,
vectors , 에 대해선 다음처럼 decompose 가능합니다.
,
이렇게 를 가지고 있고 (backward 할 때 recomputation 하려고), 모든 key, query 에 대해서 incremental 하게 진행합니다.
Recomputation
backward 시엔 에 대해 를 저장하느라 space complexity 가 필요한 건데, 위에서 저장한 가 있으면 intermediate attention matrices 를 저장하지 않고 recompute 할 수가 있습니다. 그리고 SRAM 위에서 recompute 하는 편이 훨씬 더 공간을 아끼고 빠르다고 합니다.
Kernel fusion

attention 연산은 다음과 같은 operations을 포함하는데,
matmul, dropout, softmax, mask, (another) matmul
요걸 fused kernel 하나로 개발했다는 이야기입니다. 그래서 결론은 time complexity , space complexity 는 O(N) 더 큰 정도 ( 이걸 추가로 저장하니까)가 됩니다.
Performance
GPT-2 benchmark on A100
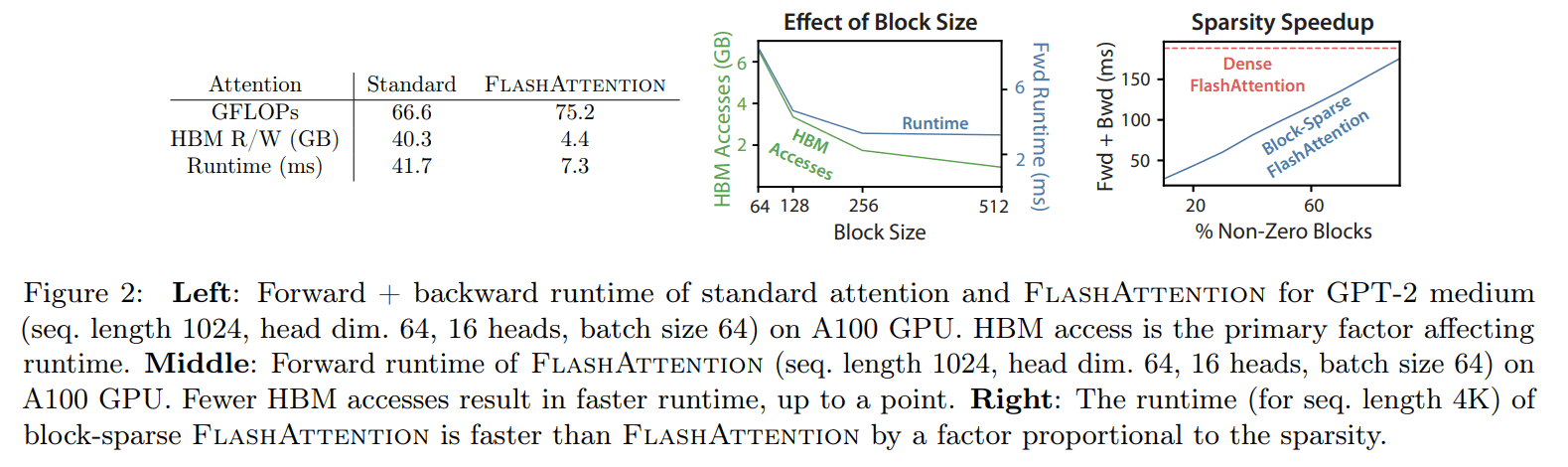
pytorch implementation (full) attention 대비 FLOPs는 recomputation 때문에 증가했지만, HBM에서 r/w 시간을 오지게(?) 줄여서 runtime 빨리진 속도를 볼 수 있습니다.
long-range Arena benchmark
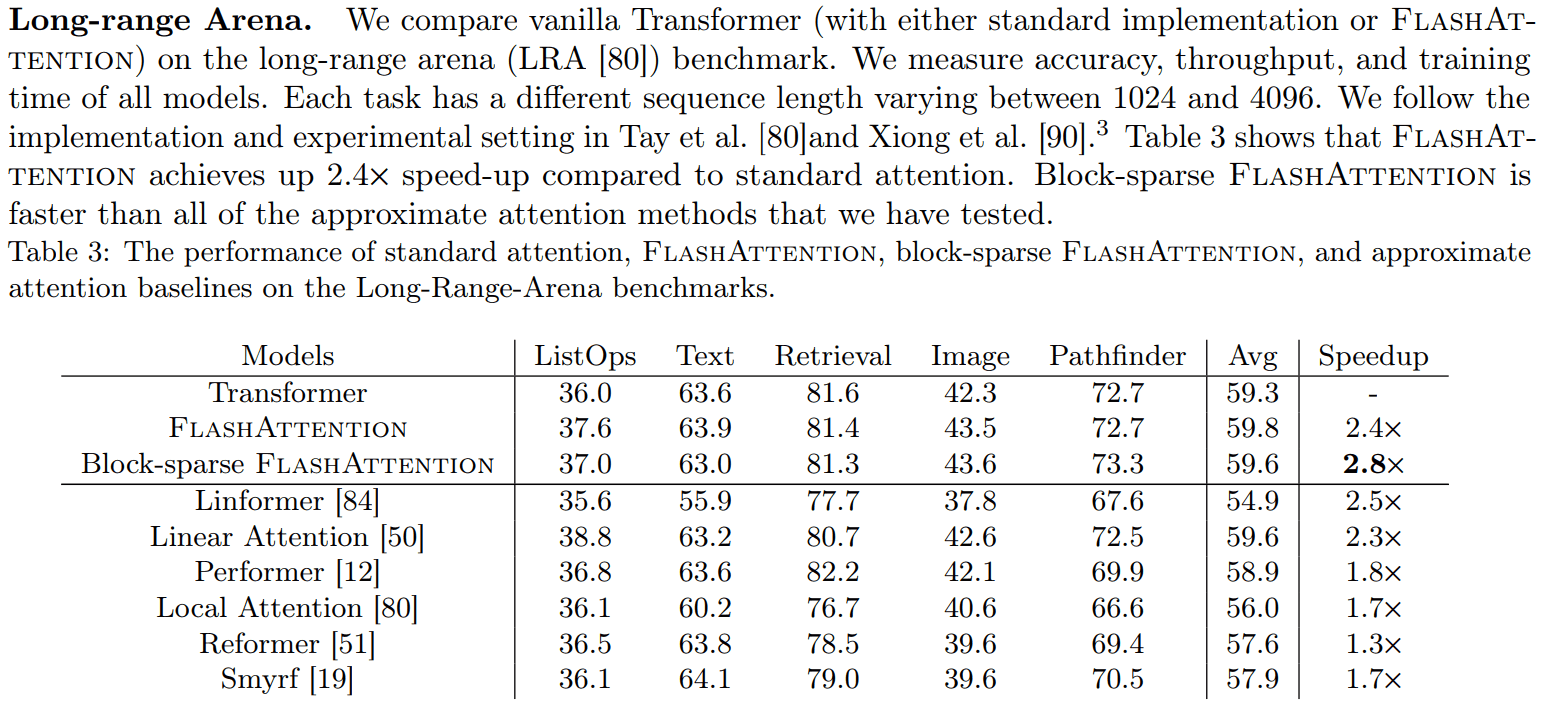
long-range benchmark 중에서도 가장 빠르면서 성능도 comparable 합니다.
runtime by sequence length
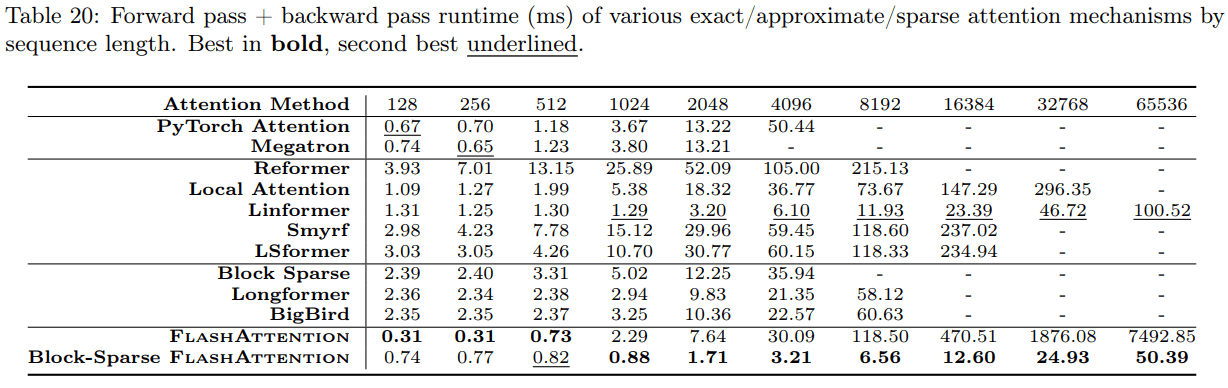
sequence 길이에 따른 runtime (fwd + bwd) 비교인데, block-sparse flash attention 기준으로 65K 에서 Linformer 보다 2배 정도 빠르다.
memory usage by sequence length
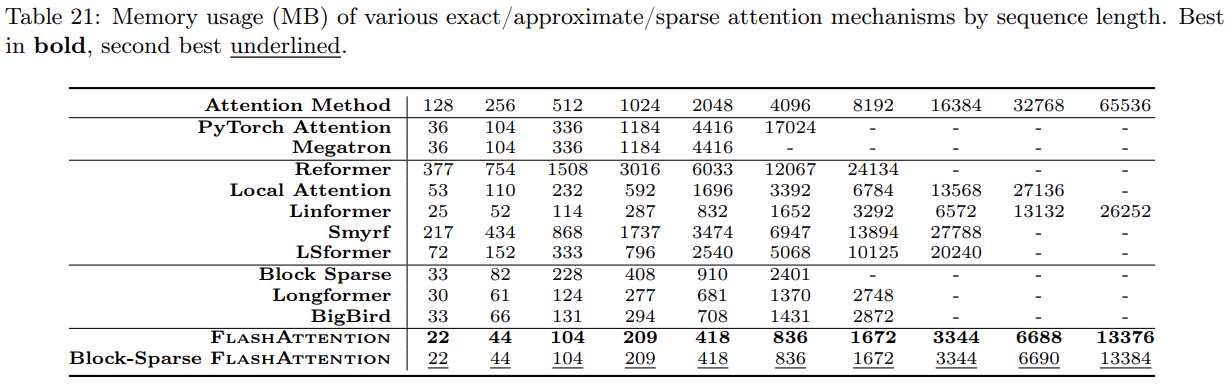
sequence 길이에 따른 memory usage 비교인데, 역시 엄청 적게 먹는다.
Conclusion
적용한 기법이나 그런 것들은 이미 알려진 연구지만 이걸 hardware-level에 adapt 해 좋은 performance를 보여준 연구인 점에서 재밌었다.
논문 limitations 에도 나와 있지만, 사용성 측면에서 cuda 구현체라 컴파일해 사용해야 하고, architecture 마다 I/O performance 도 다르고 각각 적합하게 구현해 줘야 한다는 점에서 약간 아쉬운 점이 있다 (실험 측면에서 amphere architecture 이외에서 benchmark 가 더 있으면 좋겠다는 생각).
결론 : 굳굳