
TL;DR
최근에 NVLabs 에서 VAE 관련 논문이 하나 나왔는데, 매주 월요일이 회사 짬데이라고 개인 or 팀 끼리 공부하고 싶은 주제 공부하고 공유하는 문화가 있어서, 마침 잘 돼서 논문 리뷰를 해 봅니다.
paper : arXiv
code : github
Related Work
VAE 관련 연구들이 엄청 많아서, 요 논문과 직접 연관이 있는 것들만 적어보면
- IAF-VAEs (VAE w/ Invertible Autoregressive Flows) : paper
- VQ-VAE-2 (Vector Quantized Variational AutoEncoder v2) : paper
- BIVA (Bidirectional-Inference Variational AutoEncoder) : paper
Difference
논문에서 previous works 와 this work 의 차이를 related work 에 적힌 3 개의 연구와 비교를 합니다.
요약하면 아래와 같습니다.
VQ-VAE-2 vs NVAE
비슷한 점은 둘 다 high quality image 생성이 가능하다는 점
| diff \ work | VQ-VAE-2 | NVAE |
|---|---|---|
| objective | VAE objective | |
| latent variable | up to 128x128 (big) | small |
IAF-VAEs vs NVAE
statistical models (hierarchical prior, approximate posterior) 컨셉을 IAF-VAEs 에서 가져온 것은 맞는데,
| diff \ work | IAF-VAEs | NVAE |
|---|---|---|
| statistical models | neural network | |
| posterior | x | parameterized |
| large-scale | x | o |
BN (Batch Normalization) in VAE?
이전 연구들에선 BN 이 instability 를 cause 해서 사용을 지양했는데, 이번 엔구에선 BN parameter 를 적절하게 사용하면 오히려 좋은 성능이 나온다 라고 하더군요.
Novelty
위와 같은 차이점들에 대해서 이번 연구는 요약해서 크게 3 가지 novelties 를 가집니다.
Network Design
이전 Hierarchical VAE 연구들은 hierarchical 한 요소들을 objective term 이나 level 에서 고려헀지만,
이번 연구에서는 statistical models 을 network design 자체에 녹여냈다.
Stability
hierarchical groups 수가 증가, input image size (high resolution) 가 커 지면서 stabilization 이 issue 가 되는데, 이를 직접 디자인한 (1) network modules, (2) approximate posterior 를 parameterize 함으로 문제 해결.
Efficiency
효율적은 operation 사용 (e.g. depth-wise separable convolution at decoder) 으로 memory 를 아끼고 성능도 잡아냈다.
% 저자 왈 depth-wise separable conv 를 decoder 에 사용했을 땐 성능이 좋았는데, encoder 에 사용했을 땐 성능이 오히려 안좋았다고 캅니다.
Introduce
간단하게 deep hierarchical VAE 를 review 하고 넘어가면,
approximate posterior 와 prior 를 증가시키기 위해, latent variables 를 총 개의 disjoint groups 으로 나눕니다.
그리고 prior 와 approximate posterior 는 이렇게 써 볼 수 있을텐데, (물론 두 distributions 은 Normal 을 따른다 가정한다)
그럼 에 대한 lower bound 는 아래와 같이 쓸 수 있겠죠...?
한번 더 적어보면, 아래가 이제 group 까지의 approximate posterior 가 되는 겁니다.
그럼 여기서 , 를 어떻게 neural network 로 구현할 지가 이번 연구에서 포인트 입니다.
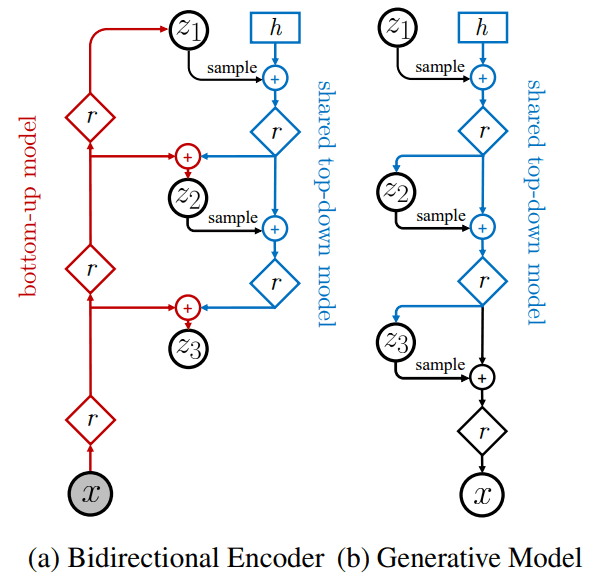
Architecture
아래 이미지와 같이 Bidirectional Encoder () 와 Generative Model ()이 있는데,
level 에 맞게 각 group 에서 sample 해 와서 add 하는 연산을 합니다.
또한 computation cost 를 줄이기 위해 Bidirectional Encoder 에 있는 top-down model 부분은 Generative Model 하고 weight-share 하네요.
Residual Cells for VAE
일반적으로 long-range correlations 를 잘 잡아내기 위한 방법으론 hierarchical multi-scale model 을 사용하는 건데, 그냥 이걸 썼다는 정도 입니다.
Residual Cells for Generative Model
network 의 receptive field 크기를 늘릴 수록 long-range correlations 을 잡는데 유리하다고 설명하는데, 일반적으로는 encoder / decoder 에 사용된 residual network 안에 convolution kernel size 를 늘리면 되겠지만, 그냥 늘리면 computation 이 엄청 늘어나니까, 이걸 depth-wise separable convolution 을 사용해 해결합니다.
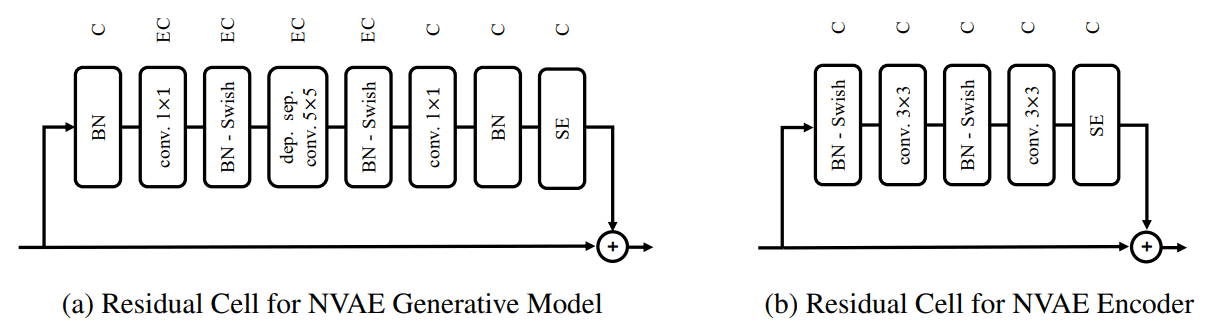
MobileNet-V2 에서 언급되었던 것 처럼, depth-wise convolution 하나만 으로 대채만 하는 건, 각 channel 따로따로 동작하는 연산특 때문에 표현성(?)에서 제한이 있어서, 위 그림처럼 conv 1x1 으로 채널을 뻥튀기 해 준 후에 depthwise conv 5x5 를 적용합니다.
BatchNormalization
위에서 언급했듯, BN 은 training instability 때문에 BN 대신 WN (Weight Normalization) 을 사용했는데,
이 논문에서, 실제 BN 의 문제는 evaluation 시, slow-moving running statistics 값 때문에 shifted 돼서, output 이 dramatic 하게 바뀔수 있다는 점이라 말하면서, 이 문제를 해결하기 위해 BN momentum 값을 batch statistics 을 빠르게 잘 잡도록 변경을 해 줬다고 합니다.
또한, scaling parameter 에 norm regularization 도 해 줬다고 합니다.
Residual Cells for Bidirectional Encoder
encoder 에서는 depth-wise convolution 이 효과가 없어서 그냥 regular convolution 사용했다고 합니다.
Taming the Unbounded KL Term
deep hierarchical VAE 를 훈련하는데 있어, unbounded KL 를 optimize 하기엔 어렵다는 말을 쭉 합니다.
그래서 KL 를 잘 optimize 하고 stable 하게 훈련할 수있는 방법들을 제안합니다.
Residual Normal Distributions
가 variable in prior 가 normal 이라 하면,
아래와 같이 정의해 볼 수 있습니다.
여기서 delta 들은 prior 와approximate posterior 의 relative location & scale 입니다.
만약 decoder output 인 가 bounded below 면, 위 KL term 이 공식에 나온 것 처럼, encoder output 인 relative parameter 에 영향을 많이 받게됩니다.
즉, 가 absolute location & scale 일 때, 요 KL term 으로 minimization 하기 쉬워지는걸 의도했네요.
Spectral Regularization
위에서 제안한 Residual Normal Distributions 만으로 stablize 하기 어렵다고 생각해 (아직 unbounded 기 때문), bound KL 을 만들기 위해, input changes 에 output 이 dramatic 하게 변하면 안된다는게 보장돼야 합니다 ~> smoothness. 그래서 이 연구에선 Lipschitz constant 를 regularizing 함으로 bounded 를 ensure 함을 가정합니다.
이어서, Lipschitz constant 를 측정하기는 힘드니, Spectral Regularization 을 각 layer 에 적용을 합니다. (lipschitz constant 를 minimize 해 주는 scheme 에서), loss term 에도 해당 regularization term 을 추가해서 minimize 합니다.
, 는 convolution 의 largest singular value
More Expressive Approximate Posteriors with Normalizing Flow
지금 구조는 approximate posterior 를 각 group 에서 병렬로 샘플하기 좋은 구조로 돼있는데 (상대적으로 작은 parameter 수, 등등), 조금 다르게 말하면, less expressive 하다고 말할 수 있다.
더 expressive 하게 만들기 위해 normalizing flow 몇 개를 추가해서 더 expressive 하게 만들자가 목적이다.
encoder 에만 해당 normalization flow 가 추가되면,
- IAF (Inverse Autoregressive Flows) 가능 (따른 명시적으로 inverse 해 주는 flow 필요 x)
- sampling time 도 flow 덕문에 증가하지 않을 거다.
라는 장점을 듭니다.
Experiment Result
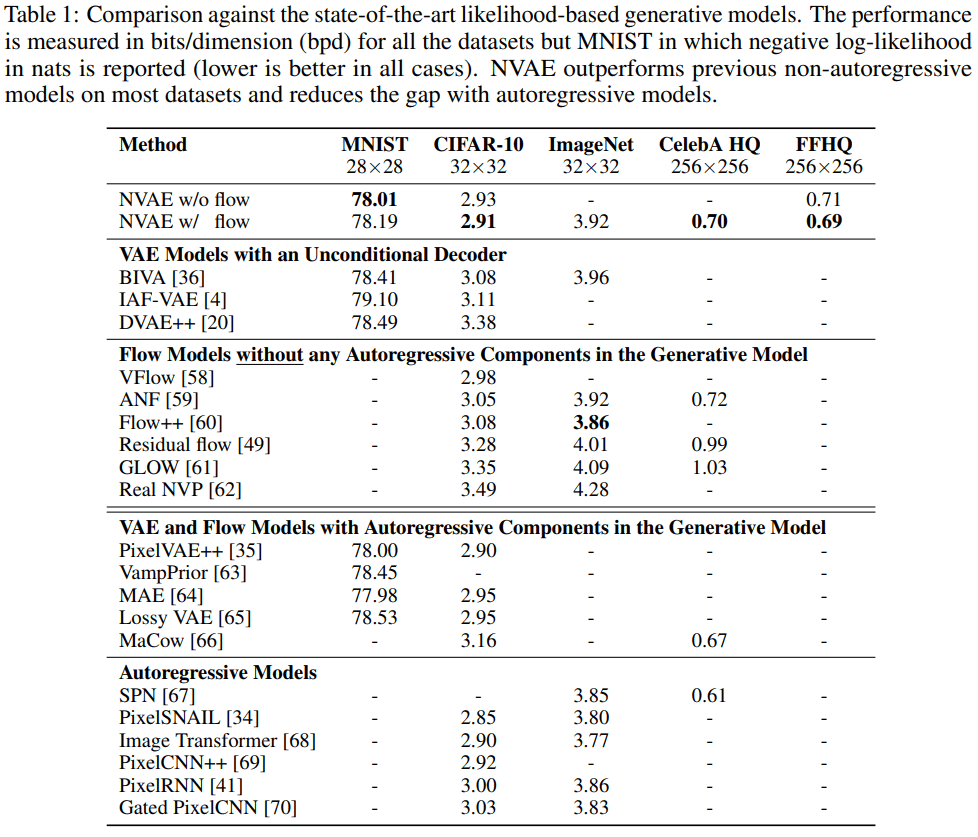
Quantitative Performance Benchmark
bits/dimension (bpd) metric 에서 SOTA 에 해당하는 성능을 보이네요.
Generations

Conclusion
개인적으로 NVIDIA 연구들은 보면 StyleGANv2 도 그렇고 network design 으로 문제를 해결해 나가는 모습을 많이 보이는데, 이번에도 어썸했다.
또, 연구를 진행하고 결과를 내는 것들이 대단하다 생각하지만, 최근 들어 VAE 쪽 논문들이 큰 novelty 없이 생산되는(?) 경향이 있었는데, 오랜만에 개인적으로 괜찮다 생각되는 AE 논문이 나온거 같아서 기분이가 좋았다.
결론 : 굳굳굳