
TL;DR
이번에 리뷰할 논문은 오랜만에 나온 YOLO 4번째 버전인 YOLOv4 논문입니다.
이번 버전은 이야기가 있는(?) 버전인데, YOLO 원 저자인 Joe Redmon 님 께서 올해 2월쯤에 twit으로 CV 연구를 그만하겠다고 선언하셨는데 (정말 YOLO 하러 가셨을까),
과연 이번 버전엔 저자에 포함될지, darknet page에는 YOLOv4 가 올라갈지 이야기가 있었는데, 이번 저자로는 빠지셨고 ㅠㅠ darknet 에는 올라갔더라고요.
쨋든, 요약하면 현재 SOTA 인 EfficientDet 과 비슷한 AP를 달성하면서 높은 FPS를 달성했네요.
Related Work
YOLO 시리즈
Introduction
이번에도 논문에서는 speed를 추구한다고 강조를 하면서
- 누구나 저렴한 GPU 장비로 학습 가능
- 빠른 operation 사용
- parallel computing 최적화 등등
여러 가지들을 고려했다고 합니다.
총 2가지의 production serving 환경을 옵션을 들면서 설명하는데,
GPU
convolution layer 에서 작은 group 들 (1 ~ 8)을 사용했다고 카네요. CSPResNeXt50 / CSPDarknet53
VPU
grouped-convolution 을 사용하고, SE Module 를 사용하지 않는다고 하네요.
Architecture
크게 아키텍쳐를 설계하고 튜닝하는 것을 논문에선 3 부분으로 나눠서 설명합니다.
- 아키텍쳐 선정
- BoF, BoS (여러가지 augmentation, activation, layer)
- 기타 튜닝
Selection of Architecture
이 논문에선 optimal 한 architecture 를 설계하기 위해 총 3가지의 balance 를 고려하는데요,
- resolution of input image
- num of layers
- num of parameters
Backbone으로 사용할 network가 ImageNet classification task에선 좋은 성능을 보일진 몰라도 Object Detection task에선 고려해야 할 점이 또 다르기 때문에, 띵킹을 해야 한다라는 점을 언급해요.
예로는 CSPResNeXt50 가 CSPDarknet53 보다 ImageNet 에선 성능이 좋아도, MS COCO dataset 에서 Object Detection 에선 반대라고 합니다.
결론적으로 CSPResNeXt50 vs CSPDarknet53 vs EfficientNet-B3 을 backbone 으로 benchmark 결과 CSPDarknet53 이 detector backbone 으로 사용하기 optimal 하다는 결론을 내립니다.

또한 SSP Module 을 추가적으로 사용하고 (receptive field 때문에), PANet 을 feature aggregation 을 위해 사용한다고 합니다. (YOLOv3 에서 쓰던 FPN 대신 사용하는 거)
최종적으로 아래와 같은 architecture 를 사용합니다.
backbone: CSPDarknet53 w/ SSPneck: PANet (path-aggregation)head: YOLOv3 (anchor-based)
마지막으로 CGBN, SyncBN 같은 multi-gpu / TPU 환경같이 비싼 환경에서 사용하는 operation 들은 사용하지 않았다고 합니다.
정말 누구나 훈련할 수 있다고 강조를 하네요 ㅋㅋㅋㅋ (그런데 1080ti, 2080ti 1개 도 없는 게 현실)
Selection of BoF and BoS
여기선 모든 layer 들 loss, metric, augmentation 모든 기법을 나열하면서 괜춘한 걸 고르는 작업을 합니다.
결론적으로 비싼 operation 들, 비싼 장비용 operation 들은 제외하고 누구나 써 볼 수 있는 operation 들을 고른 결과,
regularization method 로 DropBlock 을 사용했답니다.
Additional improvements
여기선,
- 새로운 augmentation 기법들과 SAT(Self-Adversarial Training)
- genetic algorithm 으로 hyper-parameter 튜닝
- 효율적인 훈련을 위해 디자인 변경 -> SAM, PAN module 들 수정, BN -> CmBN (Cross mini)
1
결론적으로 기존 CutMix 는 2장의 이미지끼리 blend 하는데, Mosaic 은 4장의 이미지를 섞기 때문에 더 좋아서 (둘 다) 쓴다. (large mini-batch 사용을 안 해도 된다 등등의 이유)
SAT 는 구글에 찾아보세요~ (귀찮)
3
SAM 에서 spatial-wise attention 을 point-wise attention 으로 변경 PAN 에서 shortcut 을 concat 으로 변경
이유는 나와 있지 않은데, SAM 같은 경우엔 그 작은 parameter 몇 개 줄여보겠다는 의도인 것 같고, PAN 에 concat 은 성능 측면인 것 같네요. (뇌피셜)
Summary
정리 함 다시 해 보면
Architecture
backbone: CSPDarknet53 w/ SPPneck: PANhead: YOLOv3
Uses
적용한 것들을 파트(?)별로 정리해 보면 아래와 같습니다.
- Bag of Freebies (BoF) for backbone
- augmentation : CutMix, Mosaic
- regularization : DropBlock
- etc : class label smoothing
- Bag of Specials (Bos) for backbone
- activation : Mish
- network : CSP, MiWRC
- Bag of Freebies (BoF) for detector
- augmentation : Mosaic
- regularization : DropBlock
- loss : CIoU
- layer : CmBN
- lr scheduler : cosine annealing
- etc : SAT, eliminate grid sensitivity, multiple anchors for a single gt
- Bag of Specials (Bos) for detector
- activation : Mish
- module : SPP, SAM, PAN
- loss : DIoU-NMS
Experiment Result
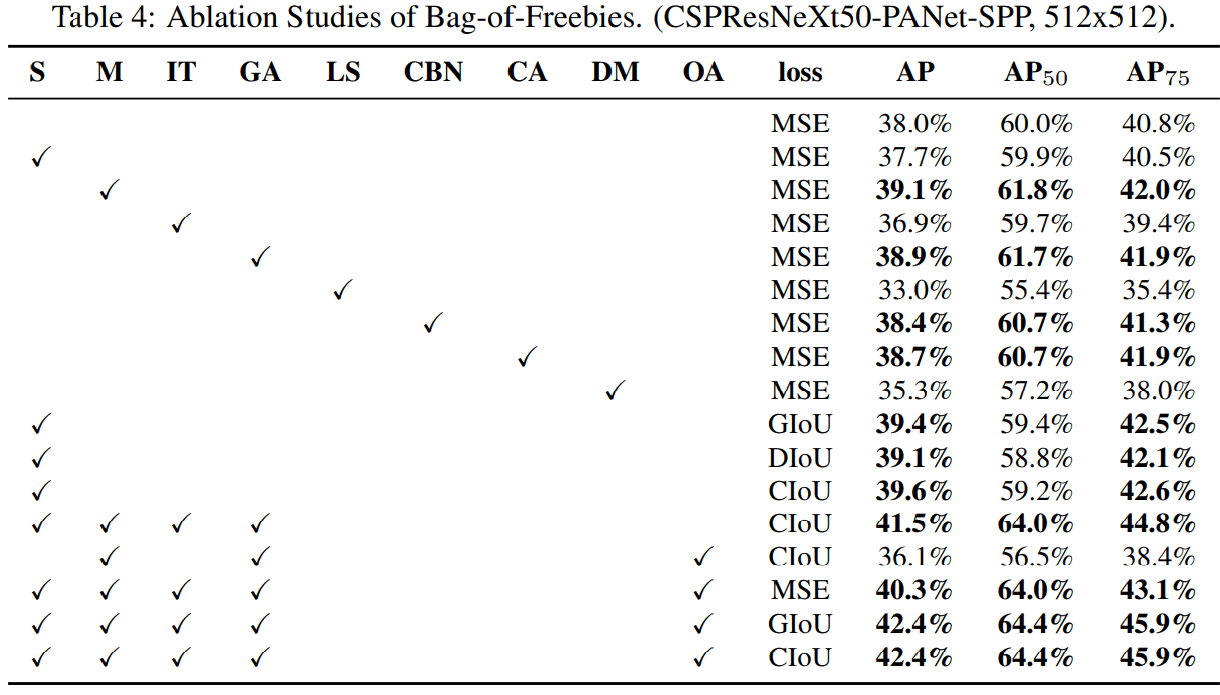
Bof Benchmark
위에 있는 모든 요소들을 benchmark 한 표.
AP, FPS Benchmark
각 GPU architecture 별로 AP, FPS benchmark 를 했는데, 아래 V100 (volta arch)에서 테스트한 결과.
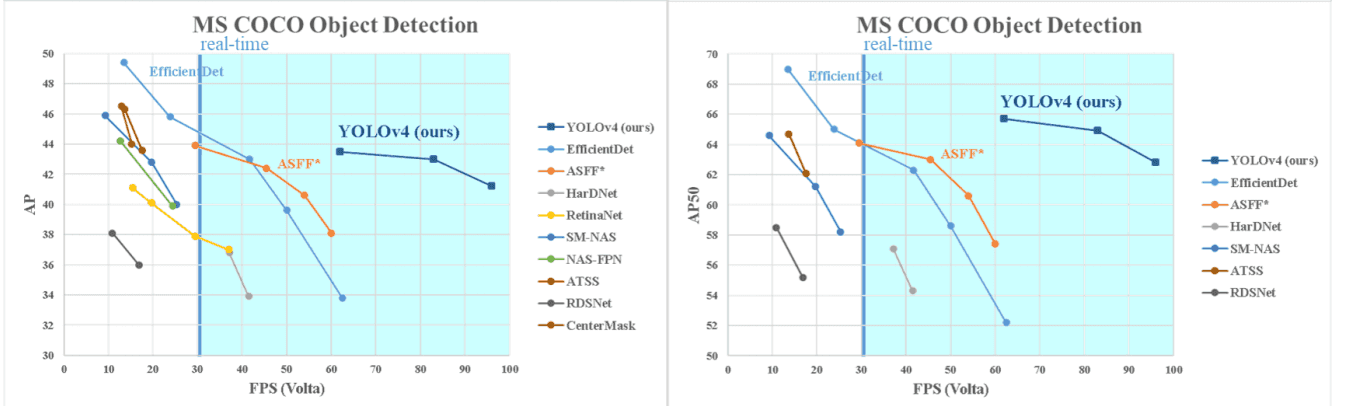
빠르네요
Conclusion
이번 논문은 정말 모든 case 들을 하나하나 고려하려는 게 보였고, 설명도 최대한 low-level(?) 하게 하나하나 스킾하지 않고 다 짚고 넘어가서 뭔가 투머치 같지만 좋았어요
또 정말 모든 부분 하나하나 튜닝한 점이 꽤 인상적이었어요. 온갖 힙한 것들도 사용하고.
결론 : 굳굳