
TL;DR
이번에 리뷰할 논문은 ELECTRA 란 google ai 에서 3월에 발표한 논문인데, 재밌는 approach 를 하고 있어서 가져와 봤습니다.
ELECTRA paper : OpenReview
google ai blog : blog
Related Work
이전 trend 들 5 개 정도만...
BERT : paper
XLNET : paper
RoBERTa : paper
ALBERT : paper
T5 : paper
Introduction
간단하게 이번 ELECTRA paper 에서 이전과 다른 점 3 가지를 정리하면
-
input 을 masking 하는게 아닌 generator 로 token 생성 (masking 효과)
-
token ID 를 예측하는 게 아닌 discriminator 로 각 token 이 generated 됐는지 예측
-
기존 MLM 보다 더 좋음. (small MLM, ...)
Architecture
Previous Story
이전 LM 들을 보면 DAE 형태로 학습을 하고 (masked input 을 복원), BERT 같은 경우에는 masking 때문에 example 당 token 의 15% 밖에 학습이 안돼서 학습 비용이 꽤 컸어요.
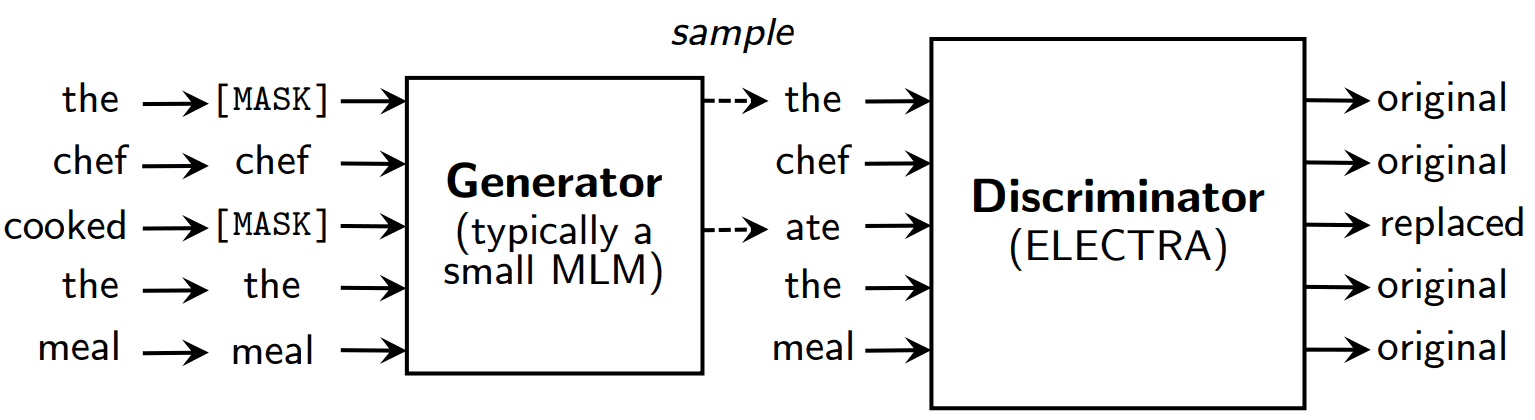
그래서 위 문제를 해결하려고 ELECTRA에서 replaced token detection task 를 제안했는데, masking 하는 대신, 작은 MLM (masked language model ~ generator) 으로 생성된 output 으로 일부 교체 하고 discriminator 를 둬서 이게 replaced token or not 인지를 예측하게 학습했습니다.
장점 으로는
- MLM 자제가 작은걸 사용 -> 연산이 더 빨라짐
- masked 된 부분만이 아닌 전체 token 에 대해서 discriminate -> 학습 효율 증가
Method
generator / discriminator 로 GAN 과 유사해 보이는데, 해당 network 구조만 그렇고 실제로 adversarial 하게 훈련하지는 않습니다.
각 network encoder 는 transformer 로 구성되어있고,
generator 는 각 token 에 대한 softmax 값을 output 로 주고
discriminator 는 각 token 에 대해 replaced / not replaced 를 예측합니다.
Model Extensions
Weight Sharing
- generator 하고 discriminator 크기가 같으면 weight sharing
- 그런데 실험 결과로는 크기가 같지 않고 small generator 를 사용하는게 훨 좋았음
- 그래서 small generator 를 사용하는 경우엔 token embedding table 만 weight sharing 을 함
Small Generators (MLM)
- generator / discriminator 크기가 같으면 기존 MLM 보다 2 배 커짐
- 주로 generator 가 discriminator 크기의 x0.25 ~ x0.5 일 때 괜춘함
- 간단한 uni-gram generator 도 시도를 해봄
- adversarial 하게 훈련하는 건 discriminator 에게 꽤 challenging 한 일이여서, 실제 실험결과도 성능이 덜 좋음
Training Algorithms
- 처음 n steps 는 generator 만 훈련
- generator weight 로 discriminator 초기화 -> generator freezing 후 discriminator 만 훈련
Small Models
효과적으로 훈련하려고 아래와 같은 hyper-parameters 사용
- sequence length (512 -> 128)
- batch size (256 -> 128)
- hidden dims (768 -> 256)
- token embedding (768 -> 128)
아래 Exp Result 에 결과첨부
Large Models
BERT-large 와 똑같은 size, 하지만 training time 은 더 오래걸림.
batch size 는 2048, XLNET pre-training data 도 사용했다고 하네요. (RoBERTa 훈련할 때 사용한 데이터와 비슷)
Efficiency Analysis
크게 3 가지인데
-
ELECTRA 15% : discriminator loss 를 전체 token 이 아니라 masking 된 15% 에만 계산
-
Replace MLM : 마스킹 할 token 을
[MASK]token 으로 replace 함 -
All-Token MLM : 위에서 masking 된 token 을 predict, discriminator 에선 mask 에 대해서만 예측이 아닌 모든 token 에 대해 예측
Experiment Result
small models on the GLUE dev set
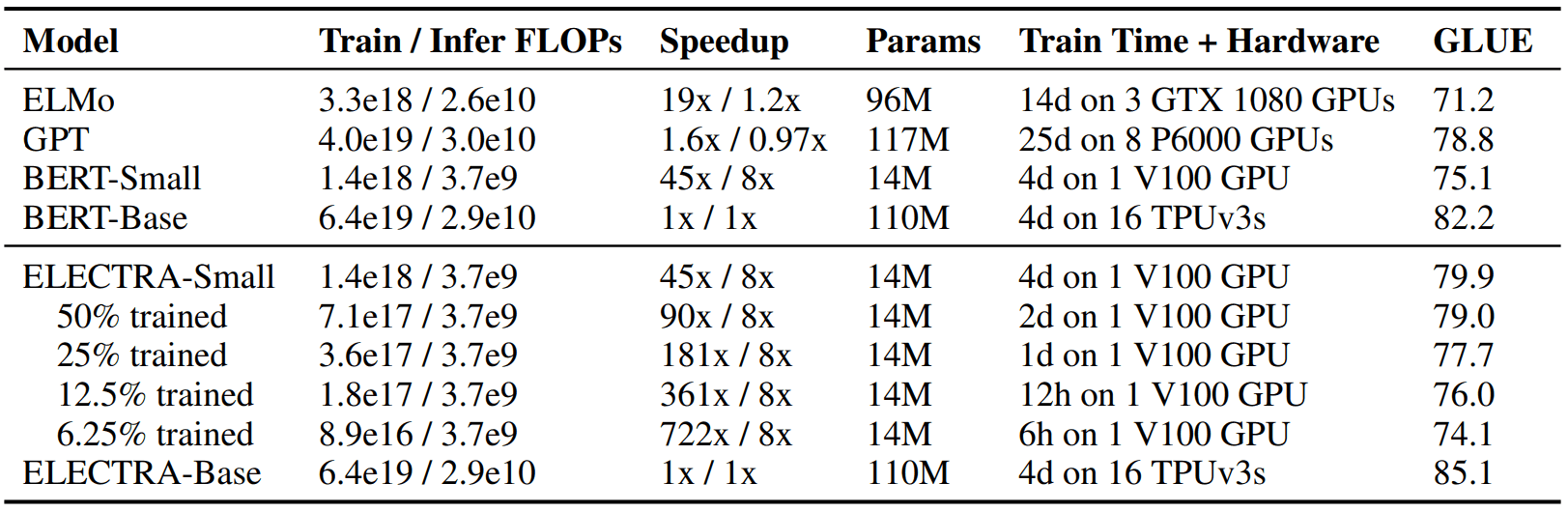
가성비 굳!
SQuAD

Efficiency

Conclusion
결론 : 굳