
TL;DR
이번 포스팅에서는 I2I translation 를 푼 StartGAN v2 을 리뷰해 보겠습니다.
평소에 Multi-Domain I2I translation task 에 관심이 많았는데, 작년에 나온 StarGAN 후속작인 StarGAN v2 가 나와서 한번 리뷰해 보려고 합니당
아래는 StarGAN v2 demo 인데, 아래와 같은 느낌입니다.

paper : arXiv
official implementation : code
Related Work
아래는 관련 task 논문들인데 한번 읽어 보세요!
- CycleGAN : arXiv
- DiscoGAN : arXiv
- StarGAN : arXiv
- MUNIT : arXiv
- DRIT : arXiv
- MSGAN : arXiv
- RelGAN : arXiv
Introduction
기존의 여러 Multi-Domain I2I translation 연구들로 대표적으로 Pix2Pix, CycleGAN, DiscoGAN, MUNIT, StarGAN 등등이 있어요. 그런데 요런 2 가지를 만족하지는 못하는 한계가 있었습니다.
- 한정된 domain 들 내에서만 translate (눈, 코, 입, 턱수염, 표정)
- 한 번에 1 가지 domain 에 대해서 translate (A->B, B->A)
즉, 기존의 Multi-Domain I2I translate task 에서는 generator 에 one-hot or multi-hot attribute vector 를 input 에 합쳐주는 방식이였습니다.
이번 논문에서는 이러한 한계들을 극복하고자 다음과 같은 목표를 제시했는데,
- 여러 domain 에 대해서 모두 translate 가능
- 특정 domain 에 대한 여러 가지 style 에 대해서 translate 가능
요런 것들을 가능하게 합니다.
Architecture
먼저 아래는 StarGAN v2 architecture 간단한 overview 인데, 아래 목적을 간단하게 설명하면 image x 와 image y 가 있다면, Generator 로 image x 에 대응되는 image y 의 각 domain 의 다양한 이미지들을 생성하는 겁니다.
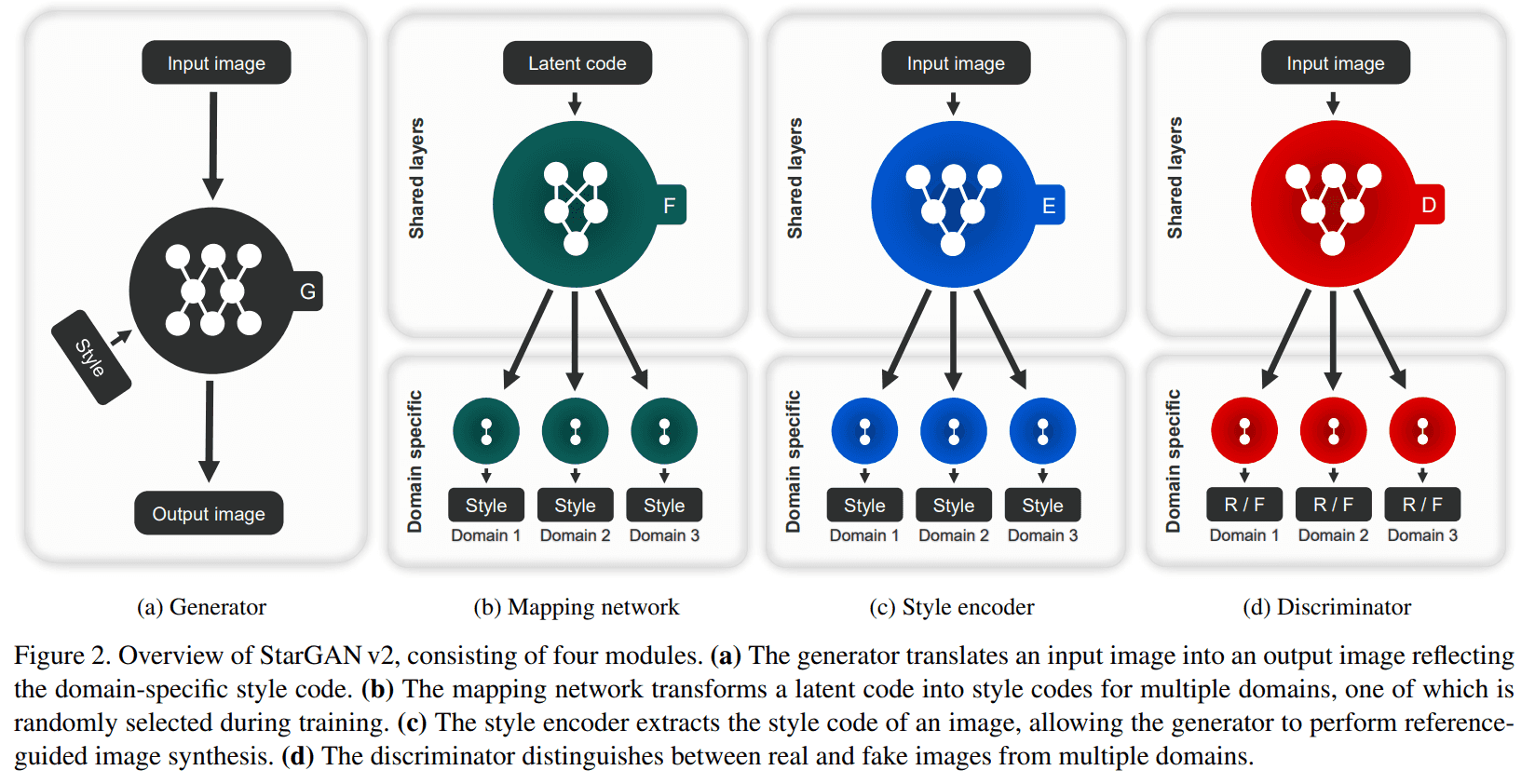
각 Network 들의 역할을 알아보면 다음과 같아요.
Generator (G)
image x 가 입력으로 들어오고 중간에 domain-specific style code s vector 가 들어와서 output image 를 만듭니다.
여기서 s 는 mapping network 나 style encoder 에서 만들어진 style vector 입니다.
즉, 이미지 한 장을 받고 어떤 style 을 받으면 해당 style 을 반영한 결과물 무언가를 만들어 내는 아이입니다.
Mapping Network (F)
mapping network, F 는 latent code z 와 domain y 에 대해서, style code를 만드는 network 인데, 대충 공식은 이렇게 됩니다.
즉, domain y 를 represent 하는 latent code z 를 style code s 로 mapping 해 주는 역할을 합니다.
F 는 간단한 여러 FC layers 들의 combination 인데, 모든 multiple-domains 에 해당하는 style codes 를 주기 위해서, multiple-outputs 를 가지는 구조랍니다.
Style Encoder (E)
image x 와 domain y가 있다면 E 는 image x 에서 style information 을 추출하는 역할을 해요.
E 는 reference image 에 대해서 다양한 style code 들을 생성하는 역할을 해요. 이렇게 생성된 style code 들을 G 에서 이미지를 생성할 때 사용됩니다.
% E 도 위의 F 와 똑같은 multi-task scheme 을 따릅니다.
Discriminator (D)
D 도 위와 같은 scheme 으로 multi-task wise 한 구조를 가집니다. 즉, multiple output branch 를 가집니다.
Technical Review
Adversarial Loss
GAN loss 같은 경우엔 WGAN, WGAN-GP, hinge-loss based gan loss 가 아닌 vanila gan loss 를 사용했네요.
Style Reconstruction Loss
style code 를 training 하기 위해서, l1 loss 를 사용합니다. loss 에 다른 특별한 점은 없지만 하나의 Encoder 로 multiple domains 들의 feature 를 추출한다는 게 큰 특징/차이가 되겠네요.
Style Diversification Loss
style 다양성을 위해선 diversity sensitive 한 loss 로 generator 를 regularize 해야 한다고 합니다.
random latent code , 에서 생성 된 , 들을 (굳이 수식으로 쓰면 아래와 같음) image x 와 G 로 생성한 output 들의 l1 loss 를 구합니다.
논문에선 이 loss 의 optimal point 는 존재하지 않아서, 의 loss weight 를 0 까지 linearly decay 시킨다고 합니다.
Preserving Source Characteristics
위의 loss 들만으로는 생성물이 어떤 결과물이여야 하는지를 preserve 하지 못하는데, 결과물은 반드시 domain-invariant 한 특성을 가지고 있어야 합니다. 이걸 잘 하는게 목표니까요!
이 부분을 해결하기 위해선 여러 task 에서 사용하고 있는 공식 loss 인 cycle consistency loss 를 쓰죠.
Total Loss
총 4 가지 type 의 loss 를 사용해서 아래와 같습니다.
전체적으로 loss 는 간편한 편이고 zero cycle consistency loss 나 등등의 loss 를 사용하지 않아도 identity 보존이나, 등등을 잘 하나 봅니다
Architectures
Generator
처음에 독특(?)한 scheme 으로 1x1 conv2d 를 사용 해 주고, pooling 은 average pool, up sample 은 nn interpolation 을 사용. encoder part 에는 instance normalization (IN), decoder part 에는 adaptive instance normalization (AdaIN). 유명한 convention(?) 이니 norm 위치 설명은 여기까지.
마지막 activation 은 tanh 나 sigmoid 로 scaling 하지 않고 model 자체가 color range 를 학습하도록 했답니다.
개인적으로도 image generation task 에서 이렇게 scaling 하지 않았을 때 더 좋은 결과가 나왔던 경우가 많았던 것 같아요

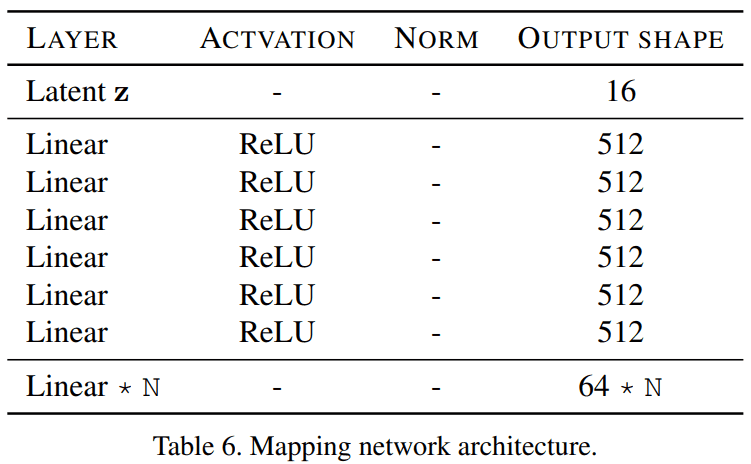
Mapping Network
전체적인 구조는 16 dims 의 latent z 를 받고, 512 dims 의 fc layers 6 개를 통과하고 64 dims 의 style code 로 projection 하네요. (N 은 branch 개수)
latent z 는 standard gaussian distribution wise 하고 실험 결과, 이번 task 에 pixel / feature normalizations method 들의 성능이 별로 안좋았다고 캅니다.
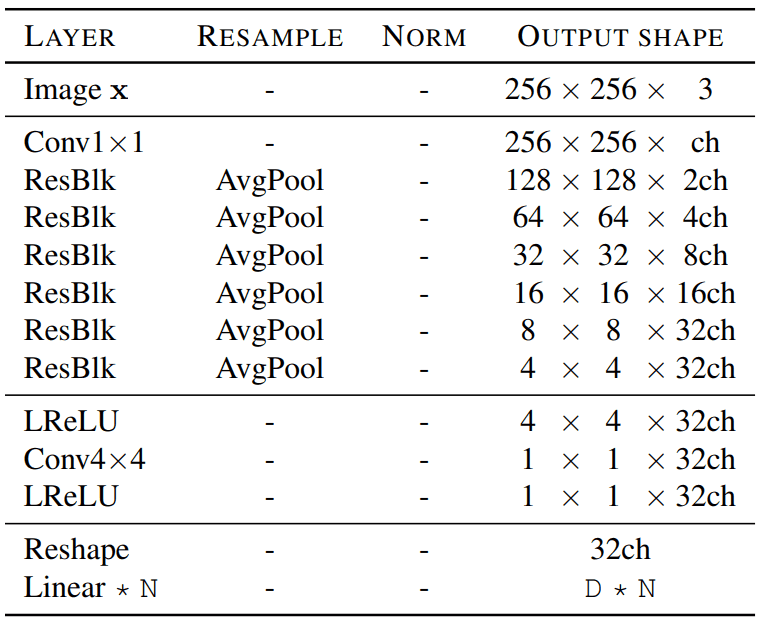
Style Encoder & Discriminator
평범한 구조인데, 특이점은 normalization 을 사용하지 않았고, PatchGAN wise 하게 접근 하지 않았다는 점입니다.
또한, conditional 보다 multi-task discriminator 가 더 좋은 성능을 보인다고 하군요.
Spectral Normalization (SN) 에 대한 언급은 없네용
Parameters
adversarial loss 엔 R1 regularize (w/ = 1) 를 하고,
loss weight 는 뭐 적당히
Adam optimizer param 으로 beta1, beta2 = (0, 0.99), lr = 1e-4 (for G, D, E) / lr = 1e-6 (for F)
weight initialize 는 HE initlaizer 로 bias 는 0, AdaIN layer 의 bias 는 1 로 설정 했답니다.
Experiment Result
이전 여러 method 들 (MUNIT, DRIT, MSGAN) 과 비교를 위해서 여러 evaluation metrics 과 2 개의 perspectives 로 image synthesis performance 를 비교해 봤는데, latent-guided synthesis, reference-guided synthesis 입니다.
간단하게는, noise 로 부터 얼마나 이미지를 잘 생성하는지, reference image 로 부터 얼마나 feature 를 잘 뽑아서 generate 하는 지를 보는 겁니다.
dataset 은 CelebA-HQ 와 AFHQ 를 사용했답니다.
정량적인
이쪽 task 에서 주로 많이 사용하는 정량적인 metric 으로 여러 개가 있는데 Frechet Inception Distance (FID), Learned Perceptual Image Patch Similarity (LPIPS) 을 사용했습니다.
Latent-Guided Synthesis
값만 간단하게 비교하면 StarGANv2 가
CelebA-HQ 에서는 FID 18.0, LPIPS 0.428 AFHQ 에서는 FID 24.4, LPIPS 0.524 가 나왔는데,
각 dataset 의 real images 의 FID 는 15.0 / 13.1 인 수준입니다. 이전 method 들 보다 성능이 훨씬 좋고 거의 실사 이미지와 비슷하다고 볼 수 있죠

Reference-Guided Synthesis
값만 간단하게 비교하면 StarGANv2 가
CelebA-HQ 에서는 FID 20.2, LPIPS 0.397 AFHQ 에서는 FID 19.7, LPIPS 0.503 가 나왔는데,
각 dataset 의 real images 의 FID 는 15.1 / 13.1 인 수준입니다. 이전 method 들 보다 성능이 훨씬 좋고 (x2, x3.5) 거의 실사 이미지와 비슷하다고 볼 수 있죠

아래는 CelebA-HQ 로 트레이닝을 하고 FFHQ 로 inference 한 결과물인데, dataset 에 distribution gap 이 있을 텐데도 reference image 의 style 을 잘 잡네요.

정성적인
AMT
요즘 핫한 evaluation method 인데, 저번 paper review 때도 소개했었습니다.
진행 방식은 다음과 같은데, (총 100 문제, 10 명)
source 와 reference 이미지 pair 로 주고 각 method 들로 생성한 이미지를 주고,
- 어느 method 가 가장 이미지 퀄이 높고
- reference image 를 잘 고려해서 생성했는지
를 물어본 결과
CelebA-HQ data로 트레이닝 한 모델 case 에선, StarGANv2 가 quality 는 70 votes, style 은 75 votes
AFHQ data로 트레이닝 한 모델 case 에선, StarGANv2 가 quality 는 88 votes, style 은 92 votes
를 받아서 압도적으로 좋은 것을 증명했다고 캅니다.