
TL;DR
이번 포스팅에서는 ICCV 2019 에서 Best Paper Awards 에서 선정된 papers 중에 하나인 SinGAN 을 리뷰해 보겠습니다.
개인적으로 정말 재밌게 본 논문이고, ICCV 2019 논문들 중 최고였던거 같아요. 그래서 저도 간략한 overview 와 technical review 를 해 보려고 합니다.
소개 전에 간단하게 SinGAN 으로 뭘 할 수 있는지 보면, 단 한 장의 이미지로 realistic 한 image manipulation 들을 생성할 수 있어요.


paper : arXiv
official implementation : code
Introduction
기존 GAN 들을 대부분의 연구들을 보면 얼굴, 침실, 풍경 등 한 가지 종류에 focus 한 게 대부분이고, 주로 많은 데이터를 요구했습니다.
다양한 종류의 object 를 생성하는 것은 여전히 잘 못하고 있고, 이런 문제를 해결할려고 conditional 하게 생성을 하거나 (e.g. cGAN), task 를 특정하는 등의 방법으로 문제를 해결하려 했습니다.
왜냐면 이전 방법들로는 적은 수의 데이터와 여러 종류의 데이터의 distribution 을 잘 학습하기엔 엄청 어려웠어요
그럼 이런 문제들을 어떻게 하면 해결할 수 있을까에서,
'단 1 장'의 이미지로 GAN 을 훈련할 수 있을까??
이런 이번 논문인 SinGAN 이란 concept 이 나오게 됐습니다. (멋지죠?)
물론 이전에 이런 노력을 안한건 아니에요. 정확히 논문 이름들은 기억이 안나는데, 대부분이 input 에 대해서 conditional 한 method 를 사용하고 있었습니다.
또한 이전에 Unconditional Single Image GAN 이라고 하면 Texture Generation 이란 task 로 유일하게 문제를 풀고 있었는데, 이 task 의 한계는 texture image 에 대해선 결과가 reasonable 한데, non-texture image 에 대해서는 별로 였어요.
하지만 이번에 소개할 논문에서는
- unconditional 하게, noise 로 부터 image 생성
- general purpose 로 natural image target (non-texture) 에도 적용 가능한 방법 제안
합니다.
물론 결과는 이전 method 들 보다 훨씬 general 하고 결과도 outperform 합니다!
Technical Review
SinGAN 에 소개된 novelty 를 1 가지로 요약 해 보면 아래와 같아요
Multi-Scale Architecture (# 2.1)
완전 새로운 concept 는 아니고, multi-scale architecture 에 대해서는 이전에 LAPGAN 이란 GAN 에서 한 번 비슷하게 소개가 되었는데, 궁금하시면 한번 봐도 좋을 것 같습니다.
Multi Scale Architecture
SinGAN 의 ultimate goal 이라고 하면, single image 의 internal distribution 을 잘 배우는 unconditional generative model 를 만드는 겁니다.
이런 것을 하려면 다음과 같은 것들을 잘 해야 할텐데,
- many different scales 로 복잡한 image structure 의 distribution 을 capture 하기
- global properties : 이미지 내 큰 objects 들의 모양과 배열 e.g.) 하늘 위치, 땅 위치
- local properties : global properties 의 details
그래서 multi-scale architecture 를 선택했습니다.

위 그림에서 x_0 가 original training image 이고, x_1 ~ x_N 가 x_0 에서 r 배 (r > 1) 씩 down-sampled image 입니다.
각 scale 에서...
Generator
noise (z_n) 와 이전 단계에서 생성된 image (~x_n-1) 를 받아서 image (~x_n) 을 만듭니다.
Discriminator
real image 와 (x_n) fake image (~x_n) 를 구분.
하나 차이(?)점이 있다면, 맨 아래 scale stage 에서는 only noise (z_N) 를 사용해서 image 를 생성합니다.
논문에서 coarse-to-fine fashion 이라고 소개를 하는데, 좀 쉽게 설명 해 보면,
아래 단계에서는 down-sampled image 를 학습하니, 상대적으로 detail 보단 global 한 feature 에 집중을 하면서 학습을 하고, 위 단계일 수록 fine feature 에 더욱 집중하게 됩니다. 동일한 receptive field 에 생성하는 image scale 이 다르니, 위 그림에 Effective Patch Size 가 달라지면서 coarse-to-fine fashion 으로 학습이 된다 입니다.
Single Scale Generation
각 G_N 부분에 해당되는 block 인데, 구조는 아래와 같습니다.
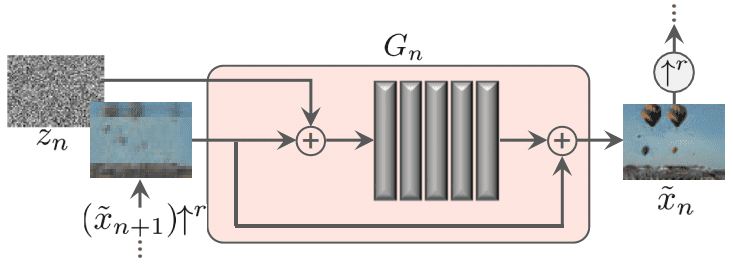
% 이전 stage 에서 up-sampled image : x_n+1
- z_n + x_n+1 가 conv 연산을 통과
- x_n+1 가 residual 하게 마지막에 연결
가 간단한 구조인데, conv block 부분을 더 자세하게 설명하면,
Conv (3x3) - BatchNorm - LeakyReLU
이 convention 으로 5 층을 쌓았네요.
처음 (coarsest scale) 엔 32 kernels / block 으로 시작을 하고 4 scales 마다 kernel 을 2 배 늘려 주었다고 합니다.
이렇게 해 준 이유는 (상대적으로 light 한 구조여서),
주로 generator 의 capacity 가 커지면 training image 를 외어버리는 경우가 생기는데, 이를 방지하려고 light 하게 설계를 한 것 같습니다.
또한 fully-convolutional 하게 설계를 한 이유는, arbitrary image size 에도 training / inference 가 가능하게끔 하려고 라고 설명을 합니다.
GAN training
이 부분이 이제 GAN을 학습하는데 있어서 제일 중요한 부분인데, 딱히 특별한 부분은 없습니다.
loss function
loss 는 adversarial loss + reconstruction loss 로 이뤄졌고
total_loss = adv_loss + alpha * rec_lossAdversarial loss
WGAN-GP loss 사용 했고. 논문에 보면, 다른 texture single image GAN 과 다르게, patch 별이 아닌 전체 이미지에 대한 loss 를 사용했더니 네트워크가 boundary conditions (SM) 를 학습할 수 있었다고 합니다.
Reconstruction loss
l2 loss 를 사용. 각 stage 에서의 rec loss 를 다음과 같이 정의가 가능한데,
rec_loss_n = l2_loss(G_n(0, (~x_n+1)), x_n)또한 ~x_n 의 역할이 하나 더 있는데, stage n 에서의 noise z_n 에 대한 std 값을 결정하는데 쓰여요. ~x_n+1 하고 x_n 의 RMSE 값을 구해서 각 scale 에 얼마만큼 더해야 하는지를 알려주는 정도로 사용된다고 합니다.
또 중요한 부분은 noise 를 넣어줄 때, 첫 단계에만 fixed noise 로 넣어주고 다른 단계에서는 noise 를 따로 만들어 주지 않았는데, image pixel difference 를 줄이려는 것에 focus 를 하려고 이렇게 했다고 캅니다.
Experiment Result
정량적인
총 2 가지의 정략적인 방법을 사용했는데,
- Amazon Mechanical Turk (AMT)
- Single Image Frechet Inception Distance (SIFID)
요즘 GAN paper 들에서 자주 사용하는 metric 들입니다.
AMT
AMT 는 사람들에게 직접 답을 하게 해서 결과를 매기는 서비스입니다. 여기서는 해당 이미지가 Fake 인지 Real 인지를 구별하게 하는 투표 방식을 사용했습니다.
여기선 2 가지 방식으로 조사를 하였는데,
- 실제 이미지와 SinGAN 이 생성한 이미지를 보여주고 어느 쪽이 가짜인지 맞히는 Paired 실험
- 둘 중 하나만 보여주고 얼마나 헷갈렸는지를 물어보는 Unpaired 실험
실험 조건은, 각 실험 당 1 초의 시간에 1 명당 50 장의 image 를 보여주었답니다.
생성한 이미지는 stage N, N - 1 에서 생성한 이미지들을 주었다는데, (논문에선 N -2 까지)
- stage N 은 noise 로 부터 생성한 이미지고
- stage N - 1 은 진짜 이미지를 축소해서 G_N-1 에 넣어주는 방식인
이런 실험에선 노이즈로 부터 생성할 때와 진짜 이미지 기반으로 생성할 때의 차이를 볼 수 있는데,
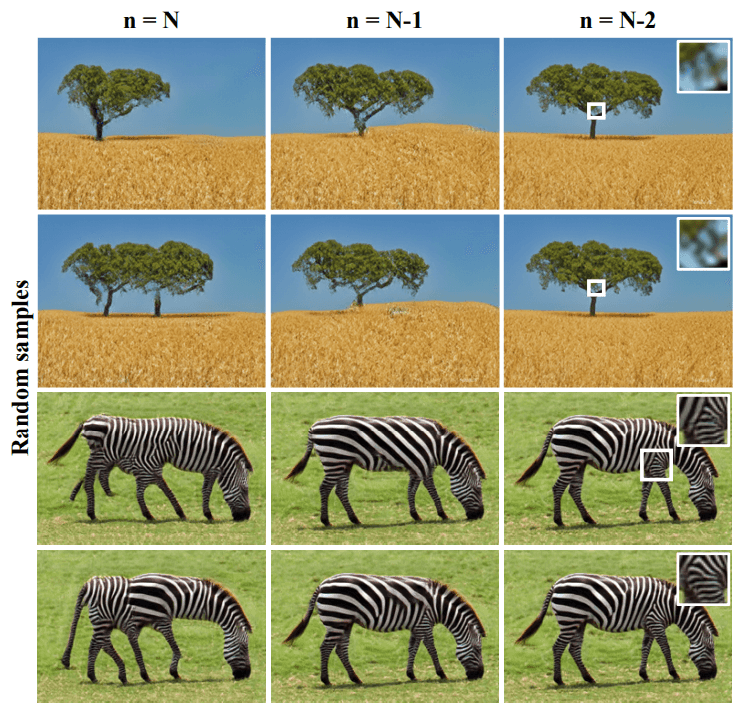
실험 결과를 보면, stage N, 노이즈로 부터 생성한 것은 원본과는 많이 다른 결과를 가져올 수 있고, stage N - 1, N - 2 는 원본 형태 유지는 되고, N - 2 같은 경우엔 texture 가 더 원본 같다는 것도 확인 할 수 있습니다.
하지만, 원본 object 의 배열을 유지한 상태에서 다양성을 보장하기엔 stage N - 1 결과물이 제일 좋다고 판단이 가능하네요. AMT perceptual study 결과도 N - 1 stage 일 때가 가장 좋습니다.
재밌는 점은 stage N - 1 일 때, confusion 이 47 % 인데, 사람이 보기에도 정말 헷갈리나 보네요.
SIFID
기존 FID 를 Single Image 에 맞게 변형해서 SIFID metric 을 제안해서 사용합니다.
각 scale 별 SIFID 를 측정하고 AMT 에서 Survey 한 결과하고 (Paired, UnPaired) correlation 를 측정해서 유의미한 metric 임을 증명하네요.
요 부분은 논문 6 ~ 7 페이지에 나와있는데, 여길 참고하세용 (귀찮아)
정성적인
총 5 개의 application 예시를 보여주고 있는데,
Single Image Super Resolution (SISR)
결과 비교를 위해 internal method 인 Deep Image Prior (DIP), Zero-Shot Super Resolution (ZSSR) external method 인 SRGAN, EDSR 와 결과를 비교했습니다.

(distortion quality 인 RMSE 가 낮을 수록 좋고, Perceptual Quality 인 NIQE 가 높을 수록 좋음)
다른 Internal Method 에 비해 RMSE 는 높지만, external method 인 SRGAN 과 NIQE 값은 comparable 합니다.
1 장의 이미지만 사용해서 이 정도 결과라서 정말 신기하네. 개인적으론 PSNR 같은 다른 metric 하고 모델 들도 넣어줬으면 좋을 것 같네요.
Paint-To-Image Style Transfer
Paint Image 로 부터 생성하는 style transfer 실험인데, quality 가 꽤괜입니다.
![]()
Editing
원본 이미지에 일부 영역들을 임의의 무언가로 넣으면 이 친구가 얼마나 자연스럽게 만들어 주는지 확인 해 주는 task 인데, 이것도 꽤 재밌는 결과를 보이네요.
아래 이미지에서 Content Aware Move 가 포토샵 기능인데, 이 것보다 잘하는 거 같네요

Harmonization
Image 2 장을 합쳤을 때 조화롭게 잘 합쳐주는 지를 보는 task 인데, 이것도 꽤 자연스럽게 잘 되는 것 같아요

Single Image Animation
한 장의 이미지를 넣어주면 짧은 video clip 을 만들어 주는 task 인데, 이 것도 자연스럽게 잘 되는 것 같네요
Conclusion
이번에 SinGAN paper review 를 해 보았는데, 이미지 한 장만 사용한다는 점과 Application 들이 정말 좋았던 paper 였어요.
개인적으론 network 설계나 등등 요소들은 조금 아쉽네요.